
A write-up of progress at the March 2021 Environment-themed hack weekend.
What problem we were addressing?
The public have access to two free, easy accessible waste recycling and disposal methods. The first is “kerbside collection” where a bin lorry will drive close to almost every abode in the UK and crews will (in a variety of different ways) empty the various bins, receptacles, boxes and bags. The second is access to recycling centres, officially named Household Waste Recycling Centres (HWRCs) but more commonly known as the tip or the dump. These HWRCs are owned by councils or local authorities and the information about these is available on local government websites.
However, knowledge about this second option: the tips, the dumps, the HWRCs, is limited. One of the reasons for that is poor standardisation. Council A will label, map, or describe a centre one way; Council B will do it in a different way. There is a lot of perceived knowledge – “well everybody just looks at their council’s website, and everybody knows you can only use your council’s centres”. This is why at CTC22 we wanted to get all the data about HWRCs into a standard set format, and release it into the open for communities to keep it present and up to date. Then we’d use that data to produce a modern UI so that residents can actually get the information they require:
- Which tips they can use?
- When these dumps are open?
- What can they take to these HWRCs?
- “I have item x – where can I dispose of it?”
Our approach
There were six main tasks to complete:
- Get together a list of all the HWRCs in the UK
- Build an open data community page to be the centre point
- Bulk upload the HWRCs’ data to WikiData
- Manually enter the HWRCs into OpenStreetMap
- Create a website to show all the data
- Create a connection with OpenStreetMap so that users could use the website to update OSM.
What we built / did
All HWRCs are regulated by a nation’s environmental regulator:
- For Scotland it is SEPA
- For Northern Ireland it is NIEA
- For Wales it is NRW
- For England it is EA
A list of over 1,000 centres was collated from these four agencies. The data was of variable quality and inconsistent.
This information was added to a wiki page on Open Street Map – Household waste in the United Kingdom, along with some definitions to help the community navigate the overly complex nature of the waste industry.
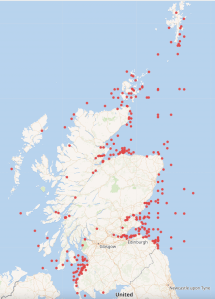
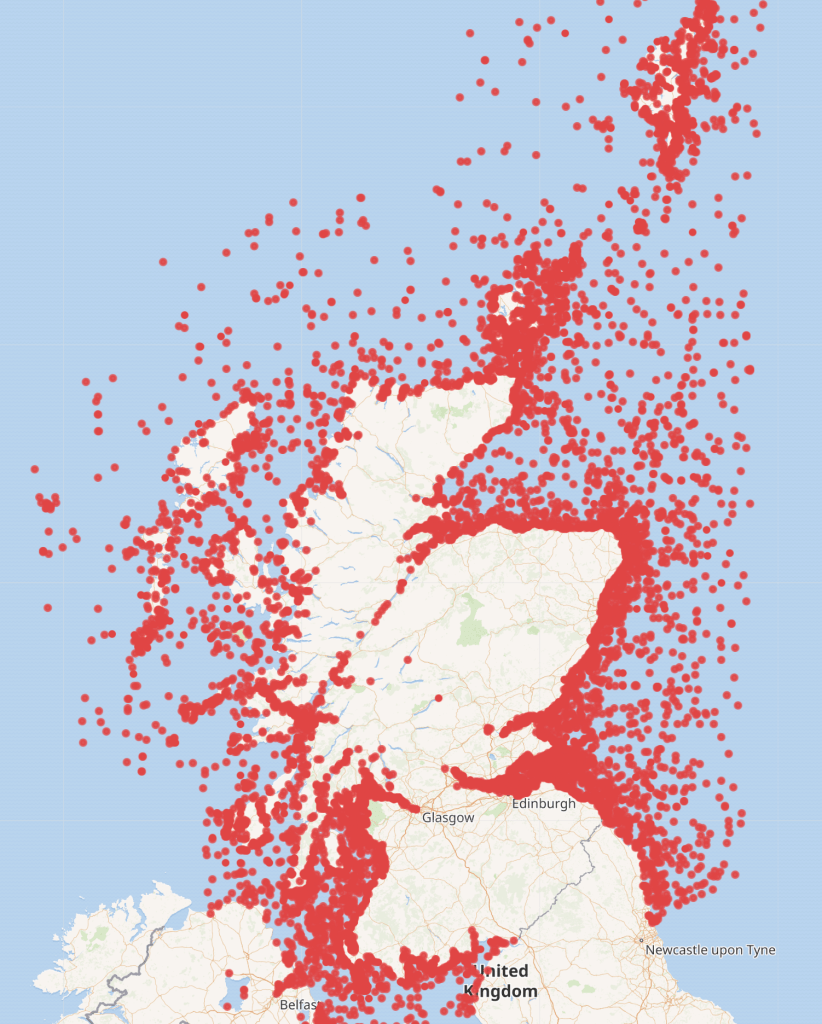
From that the lists for Scotland, Wales and England were bulk uploaded to WikiData. The was achieved by processing the data in Jupiter Notebooks, from which formatted data was exported to be bulk uploaded via the Quick Statements tool. The NIEA dataset did not include geolocation information so future investigation will need to be done to add these before these too can be uploaded. A Wikidata query has been created to show progress on a map. At the time of writing 922 HWRCs are now in Wikidata.
Then the never-ending task of locating, updating, and committing the changes of each of the OSM locations was started.
To represent this data the team built a front-end UI with .NET Core and Leaflet.js that used Overpass Turbo to query OSM. Local Authority geolocation polygons were added to highlight the sites that a member of the public could access. By further querying the accepted waste streams the website is able to indicate which of those centres they can visit can accept the items they are wanting to recycle.
However, the tool is only as good as the data so to close the loop we added a “suggest a change” button that allowed users to post a note on that location on OpenStreetMap so the wider community can update that data.
We named the website OpenWasteMap and released it into the wild.
The github repo from CTC22 is open and available to access.
Pull requests are also welcome on the repo for OpenWasteMap.
What we will do next (or would do with more time/ funding etc)
The next task is to get all the data up-to-date and to keep it up to date; we are confident that we can do this because of the wonderful open data community. It would also be great if we could improve the current interface on the frontend for users to edit existing waste sites. Adding a single note to a map when suggesting a change could be replaced with an edit form with a list of fields we would like to see populated for HWRCs. Existing examples of excellent editing interfaces in the wild include healthsites.io which provides an element of gamification and completionism with a progress bar with how much data is populated for a particular location.

Source: https://healthsites.io/map#!/locality/way/26794119
While working through the council websites it has become an issue that there is no standard set of terms for household items, and the list is not machine friendly. For example, a household fridge can be called:
- Fridge
- Fridge Freezer
- WEEE
- Large Domestic Electrical Appliance
- Electric Appliance
- White Good
A “fun” next task would be to come up with a taxonomy of terms that allows easier classification and understanding for both the user and the machine. Part of this would include matching “human readable” names to relevant OpenStreetMap tags. For example “glass” as an OSM tag would be “recycling:glass”
There are other waste sites that the public can used called Bring Banks / Recycling Points that are not run by Local Authorities that are more informal locations for recycling – these too should be added but there needs to be some consideration on how this information is maintained as their number could be tenfold that of HWRCs.
As we look into the future we must also anticipate the volume of data we may be able to get out of sources like OpenStreetMap and WikiData once well populated by the community. Starting out with a response time of mere milliseconds when querying a dozen points you created in a hackathon is a great start; but as a project grows the data size can spiral into megabytes and response times into seconds. With around 1,000 recycling centres in the UK and thousands more of the aforementioned Bring Banks this could be a lot of data to handle and serve up to the public in a presentable manner.













{kind=link}