We’ve created a review of the last year, and a look ahead to some exciting plans for 2024.
You can read more in our latest newsletter.
See you all in 2024.
Code The City is a civic hacking initiative focused on using tech and (open) data for civic good. We use hack weekends, open data, workshops, and idea generation tools. We run Data Meetups, the Aberdeen Python User Group and the annual Scottish Open Data Unconference
We’ve created a review of the last year, and a look ahead to some exciting plans for 2024.
You can read more in our latest newsletter.
See you all in 2024.
We’re delighted to announce that our Trustee and Co-founder, Ian Watt, has been elected as a Fellow of the RSA (The Royal Society for Arts, Manufactures and Commerce).
Ian was nominated in recognition of his commitment to education on tech and digital skills that can be used for social action, exemplified in his co-founding of Code the City.
Ian Watt, Code the City Trustee and Co-Founder said: “I am delighted to have been elected as a Fellow of the RSA and to be recognised on behalf of Code the City.
“Our work in opening up data, developing code openly and sharing knowledge and skills has never been more important and relevant to Scottish society which this news shows.
“In Code The City we have created and sustained a community of people who give their time generously using digital and data skills to solve societal problems.
“Whether as organisers or as participants, all contribute through activities such as our hack weekends, our local Data Meetups, our Aberdeen Python (coding) User Group, and the annual Scottish Open Data Unconference. These activities significantly help individuals share knowledge and work together on developing socially-important projects such as the national open data portal for Scotland.”
This month (September 2022) will see our 27th Hack Weekend on the topic of Education, a session of the Python User Group, and the return of the Aberdeen Data Meetup which will feature a showcase of Masters Students projects from local universities. All of our events, which are open to anyone to attend, and hosted in the wonderful ONE Tech Hub in Schoolhill, Aberdeen.
About Code The City ( SC047835)
Code The City was founded in 2014 and became a charity in 2017. We use tech and data for civic good. We believe that a world where everyone understands at least a little of how to use code and data, is a better place.
At Code The City we have a passionate group of volunteers who build new tools and services to help people in the community access existing services and even start new ones.
We work regularly with local authorities, and third sector organisations, on developing solutions to civic challenges.
More info: https://codethecity.org/about/
At Code The City 22 we started Meet Your Next MSP, a project to list hustings for the Scottish Parliamentary election. The team comprised of James Baster and Johnny Mckenzie.
James Baster had prior experience working on a similar project for the UK general election in 2015, where they listed over 1000 events in a project that was cited by many charities and campaigns. This showed him that there was interest in such a project. It also showed that many people don’t even know what a hustings areis, so the project deliberately tries to be accessible in order to introduce others to these type of events.
At Code The City 22 we built a basic working prototype; a git repository to hold the data; a Python tool to parse the files in the git repository to a SQLite database, and a Python Flask web app to serve that SQlite database as a friendly website to the public. This website invites submissions to the crowd-sourced data set by means of a Google form.
Thanks to Johnny who wrangled data from National Records of Scotland to make a dataset that mapped postcodes to areas; vital for powering the postcode lookup box on the home page of the site.
Storing data in a git repository is an interesting approach; it has some drawbacks but some advantages (moderation by pull requests and a full history for free). Crucially, it’s not a new idea and is something many people already do so it will be interesting to learn more about this approach.
Since the hackathon, the website has been tweaked, the Google form replaced with a better custom form and the website is now live!
We will run this over the next month and see how this goes.
And after the general election, the lessons won’t be lost. What we are essentially building are tools that let a community of people list events of interest together, with the data stored in a git repository. We think this tool could be applicable to many different situations.
This is project started as part of CTC21: Put Your City on the Map which ran Saturday 28th Nov 2020 and Sunday 29th Nov 2020. You can find our code on Github.
There are thousands of ship wrecks off the coast of Scotland which can be seen on Marine Scotland’s website

In Wikidata the position was quite different with only a few wrecks being logged. The information for the image below was derived from running the following query in Wikidata https://w.wiki/nDt

The project started by research various website to obtain the raw data required. Maps with shipwrecks plotted were found but finding the underlying data source was not so easy.
Data on Marine Scotland, Aberdeenshire Council’s website and on the Canmore website were considered.
Once data was found, the next stage was finding out the licensing rights and whether or not the data could be downloaded and legitimately reused. The data found on Canmore’s website indicated that it was provided under an Open Government Licence hence could be uploaded to Wikidata. This is the data source which was then used on day two of the project.
A training session on how to use Wikidata was also required on day one to allow the team to understand how to upload the data to Wikidata and how the identifiers etc worked.
Deciding on the identifiers to use in Wikidata was the starting point, then the data had to be cleaned and manipulated. This involved translating Easting and Northings coordinates to latitude and longitude, matching the ship types between the Canmore file and Wikidata, extracting the reference to the ship from Canmore’s URL and general overall common sense review of the data. To aid with this work a Python script was created. It produced a tab separated file with the necessary statements to upload to Wikidata via Quickstatements.
The team members were new to Wikidata and were unable to create batch uploads as they didn’t have 4 days since creating their accounts and 50 manual edits to their credit – a safeguard to stop new accounts creating scripts to do damage.
We asked Ian from Code The City to assist, as he has a long editing history. He continues this blog post.
Next steps
I downloaded the output.txt file and checked if it could be uploaded straight to Quickstatements. It looked like there were minor problems with the text encoding of strings. So I imported the file into Google Docs. There, I ensured that the Label, Description and Canmore links were surrounded in double quotation marks. A quick find and replace did this.
I tested an upload of five or six entries and these all ran smoothly. I then did several hundred. That turned up some errors. I spotted loads of ships with the label “unknown” and every wreck had the same description. I returned to the Python script and tweaked it to concatenate the word “Unknown” with a Canmore ID. This fixed the problem. I also had to create a checking method of seeing if our ship had already been uploaded. I did this by downloading all the matching Canmore IDs for successfully uploaded ships. I then filtered these out before re-creating the output.txt file.
I then generated the bulk of the 24,185 to be uploaded. I noticed a fairly high error rate. This was due to a similar issue to the Unknown-named ships. The output.txt script was trying to upload multiple ships with the same names (e.g. over 50 ships with the name Hope). I solved this in the same manner as with Unknown-named wrecks, concatenating ship names with “Canmore nnnnnn.”
I prepared this even as the bulk upload was running. Filtering out the recently uploaded ships and re-running the creation of the Output.txt file meant that within a few minutes I was able to have the corrective upload ready. Running this a final time resulted in all shipwrecks being added to WIkidata, albeit with some issues to fix. This had taken about a day to run, refine and rerun.
The following day I set out to refine the quality of the data. The names of shipwrecks had been left in sentence case: an initial capital and everything else in lower case. I downloaded a CSV of records we’d created, and changed the Labels to Proper Case. I also took the opportunity to amend the descriptions to reflect the provenance of the records from Canmore in the description of each. I set one browser the task of changing Labels, and another the change to descriptions. This was 24,185 changes each – and took many hours to run. I noticed several hundred failed updates – which appear to just be “The save has failed” messages. I checked those and reran them. Having no means of exporting errors from Quickstatements (that I know of) makes fixing errors more difficult than it should be.
Finally I noticed by chance that a good number of records (estimated at 400) are not shipwrecks at all but wrecks of aircraft. Most, if not all, are prefixed “A/C’ in the label.
I created a batch to remove statements for ships and shipwrecks and to add statements saying that these are instances of crash sites. I also scripted the change to descriptions identifying these as aircraft wrecks rather than ship wrecks.
This query https://w.wiki/pjA now identifies and maps all aircraft wrecks.
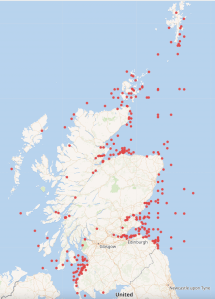
This query https://w.wiki/pSy maps all shipwrecks
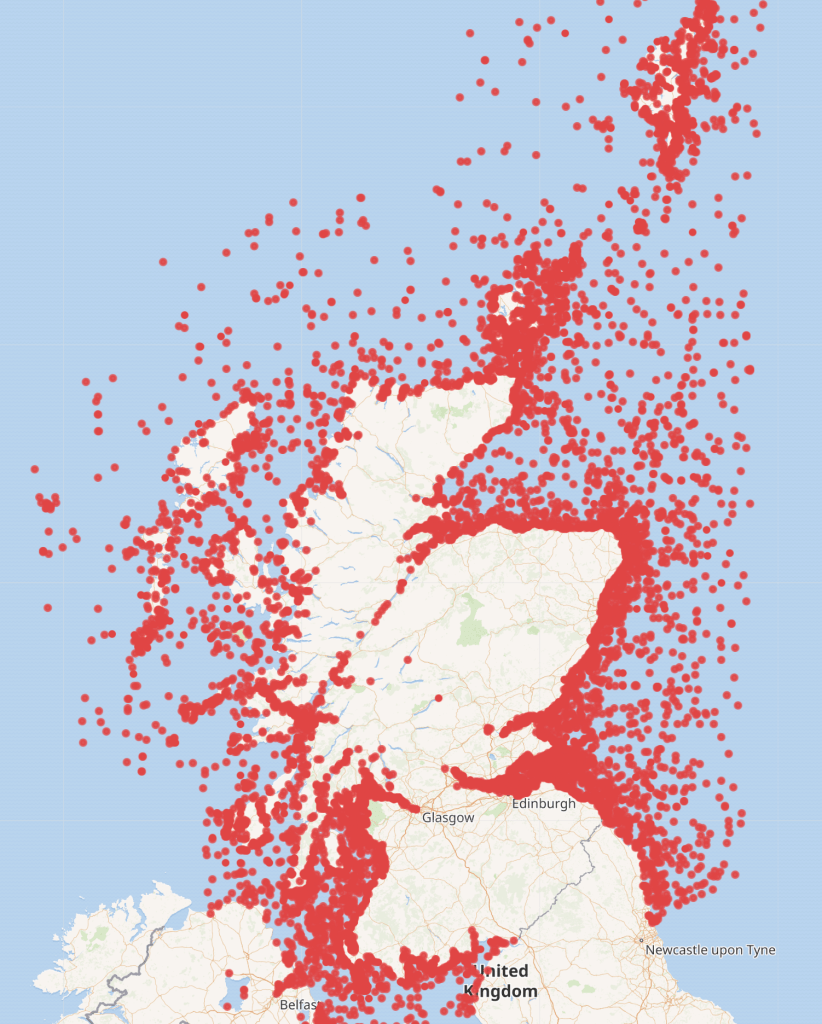
I’ve noted the following things that the team could do to enhanced and refine the data further:
Finally, in the process of working on the cleaning of this uploaded data I noticed the the data model on Wikidata to support this is not well structured.
This was what I sketched out as I attempted to understand it.

Before I changed the aircraft wrecks to “crash site” I merged the two items which works with the queries above. But this needs more work.
I’d be happy to work with anyone else on better working out an ontology for this.
We held our CTC14 Archaeology weekend, which was sponsored by Aberdeenshire Council Archaeology Service, on the weekend of 15 and 16 September 2018.
All code, and some data and documentation which were created over the weekend has been published on Github repos.
Throughout 2006 an archaeological dig of the East Kirk of the St Nicholas Church was conducted by a team led by the archaeology service of Aberdeen City Council. You can read more of the history here. A large number of skeletal remains and other artefacts were recovered. Written records were created in the form of plans, and log books, and some of these were drawn, then scanned, and a MS Access 2 Database was also created.
Since the end of the dig, some post-excavation analysis of skeletal remains, and other artefacts, has been conducted, but this is far from complete due to a lack of funds.
Following an introduction from Ali Cameron, the dig director, challenges were identified, ideas for tackling those identified, and teams formed around those.
The teams, and their projects, created a pipeline; one feeding the other.
Below we introduce the teams. Each of these will shortly be linked to individual blog posts for each team.
They had two aims:
Working from CSV files (derived from an Access 2 MDB file), JPEG diagrams, Corel Photopaint files and even using original hand-draw plans and log books, this team aimed to create a complete set of data of all excavated remains, allowing these to be plotted in 3D space using X, Y and Z coordinates.
This team set out to create a schema and mesh diagram which would use the data from team skelocator in a format which the unity burials could use.
The members of this team wanted to create a 3D model of the church interior in Unity, and to place skeletal remains accurately in the 3D space, moving from block models to accurate ones. Their initial focus was on setting up the deployment of their basics to GitHub and to speak to the other teams about what the formats of data they could work with in order to move this along faster
This team was looking at stories that would help drive any fundraising later, and exploring what data might be possible for visualisations.
The second round of updates at 5pm on Saturday saw each team make progress.
They were using Qlone for scanning from mobile phones and found it takes only a few minutes per bone – this is also the app recommend for this by Historic Scotland. However, they are blocked by the size of the paper grid that is needed under the object being scanned. An A3 sheet is not quite big enough for larger bones. Another group found it took 20 minutes with laptop to produce low res version from camera photos, and all tried pushing completed models to Sketchfab site.
They explored raw files to see what could be extracted with different tools looking at exif data and whether this could be supplemented with data from the dig books if necessary.
It appeared that there was no need for this team as Skelocator could output neutral format files, with agreed content, directly to team Unity Burials. So the team disbanded and members were absorbed into other teams.
They were experimenting with how they can manipulate data from one app to another to provide reference points for when they do have the skeletons to place in the model, and how they might show the metadata of each skeleton too.
This team were exploring how to use the Microsoft ML libraries to build a chatbot that would use FAQ information about the dig to answer questions.
The Sunday had teams coming together from 9:30-10:30 and most people returned which was good. We saw an update around noon.
The team used Qlone to scan more bones with mobiles. They discovered the resolution was high enough, even on smaller ones, to be able to notice things which hadn’t previously been noticed such as what appear to be sword cuts to a rib bone (white marks) on a person who was known to have been stabbed in the head.
This highlights the importance of scanning the bodies while they are available before re-internment at a later date. The larger scans with Qlone were found to be too big for detail as you had to stand further away and thus lost resolution.
They are now using the Python library Sloth to bring the images to life by extracting text from them and putting this into a JSON file. They also found this enabled a way to position each of the skeletons by marking their locations on the image and then creating a grid for reference from a known fixed location, which could also be used by the unity burial team.
One member worked out a convoluted, but workable, process to get images into Unity from other file formats, while another team member worked on a UI for the public to navigate the model.
They started a chatbot, but found it needs to have its data in a better format, and are starting to work with with cleaning up a list of skeletons for using with dc.js visualisations, as well as a webpage for holding the data from the other teams.
Everything is being brought together in Sketchfab so that all models can be found.
https://sketchfab.com/models/6edc98b057c740b5a66d34276ee261da/embed St Nicholas Kirk Skeleton SK820 Skull by Moira Blackmore on Sketchfab
They are exploring how to combine smaller models to create bigger ones by exporting them into another app. They discovered the limits of scaling the grid in Qlone to get the best resolution with devices, and how to use photos and a laptop to get a scan of whole skeleton using the right background cloth.
They further pulled data from processed photos with x,y,z locations from a superimposed grid that could be automated with human double-checking to make up for the lack of GPS being available for their tools in 2006, as it is now. This can then be handed to unity burials.
One member found more ways to bring in scanned data from team scoliosis, while the other improved upon the UI for the VR version and demoed the basic model to people with the VR headset.
They updated their google doc spreadsheet and pulled it into the pages at GitHub.io so that it could be queried for skeleton info and finished adding the basic visualisations of this data with dc.js while the skelebot was improved with some personality, but wasn’t as useful as it was hoped it would be.




