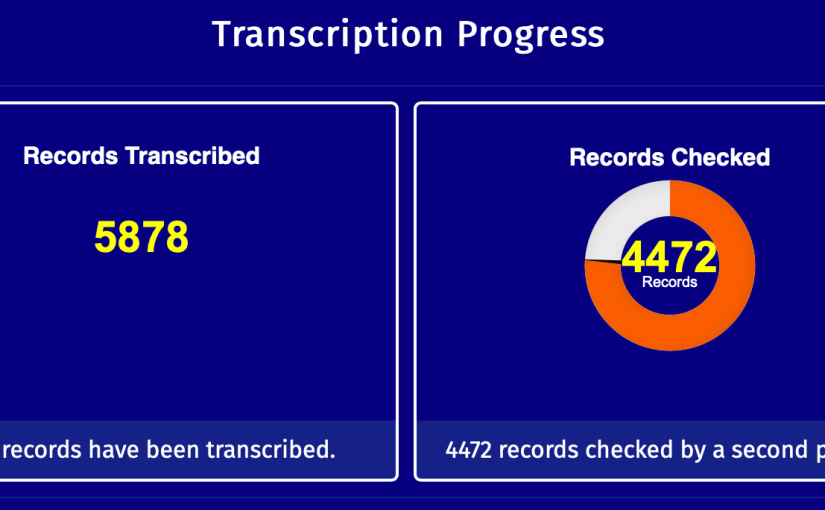
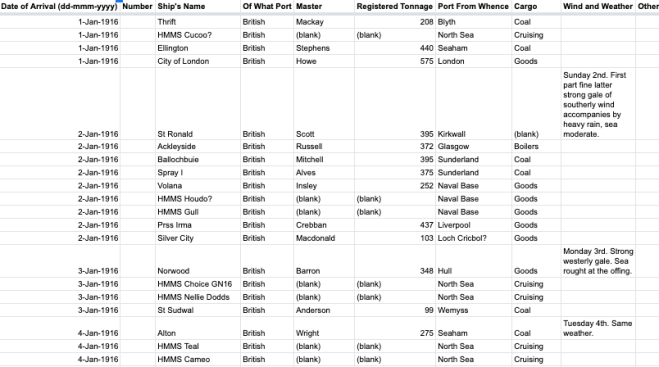
This project was one of several initiated at the fully-online Code the City 19 History and Data event.
It’s purpose is to gather data on Aberdeen-built ships, with the permission of the site’s owners, and to push that refined bulk data, with added structure, onto Wikidata as open data, with links back to the Aberdeen Ships site through using a new identifier.
By adding the data for the Aberdeen Built Ships to Wikidata we will be able to do several things including
- Create a timeline of ship building
- Create maps, charts and graphs of the data (e.g. showing the change in sizes and types of ships over time
- Show the relative activity of the many shipbuilders and how that changed
- Link ship data to external data sources
- Improve the data quality
- Increase engagement with the ships database.
The description below is largely borrowed from the ReadMe file of the project’s Github Repo.
Progress to date
So far the following has been accomplished, mainly during the course of the weekend.
- A script get_ids.py was developed to gather all the ship IDs from Aberdeen-built ships and writes them to ids.txt.
- The script get_details.py uses the IDs from ids.txt and scrapes the full ship information from Aberdeen-built ships and writes it to the file ships.json.
- The file query.rq contains code to execute a query on Wikidata Query Service to get the QID and name of every ship on Wikidata. This has been manually downloaded as all_wd_ships.json.
- The file ship_builders.py checks ships.json and constructs a list of all ship builders and a frequency count of their appearance, writing it out to ship_builders.csv.
- The file already_in_wd.py has checked for ships names in ships.json and crossed matched with all_wd_ships.json and generated a list of ships whose name indicates that they MAY be already in Wikidata.
Next Steps?
To complete the project the following needs to be done
- Ensure that the request for an identifier for ABS is created for use by us in adding ships to Wikidata. A request to create an identifier for Aberdeen Ships is currently pending.
- Create Wikidata entities for all shipbuilders and note the QID for each. We’ve already loaded nine of these into WikiData.
- Decide on how to deal with the list of ships that MAY be already in Wikidata. This may have to be a manual process. Think about how we reconcile this – name / year / tonnage may all be useful.
- Decide on best route to bulk upload – eg Quickstatements. This may be useful: Wikidata Import Guide
- Agree a core set of data for each ship that will parsed from ships.json to be added to Wikidata – e.g. name, year, builder, tonnage, length etc
- Create a script to output text that can be dropped into a CSV or other file to be used by QuickStatements (assuming that to be the right tool) for bulk input ensuring links for shipbuilder IDs and ABS identifiers are used.
We will also be looking to get pictures of the ships published onto Wiki Commons with permissive licences, link these to the Wiki Data and increase and improve the number of Wikipedia articles on Aberdeen Ships in the longer-term.
Header Image of a Scale Model of Thermopylae at Aberdeen Maritime Museum By Stephencdickson – Own work, CC BY-SA 4.0