Code The City is a civic hacking initiative focused on using tech and (open) data for civic good. We use hack weekends, open data, workshops, and idea generation tools. We run Data Meetups, the Aberdeen Python User Group and the annual Scottish Open Data Unconference
While the projects we carry out may seem a bit daunting to newcomers, everyone involved in our events carries out a vital role which is highlighted by some past attendee experiences.
As part of our commitments to making Data accessible for all we were looking to digitally archive many 19th and 20th century records that were only available physically or were missing information online. This was the main focus of our 19th and 20th Events known as ‘History + Data = Innovation’ and ‘History and Culture’ respectively. These primarily involved uploading data on a multitude of subjects to Wikidata such as Listed buildings, convict registers and March Stones, which signified the boundary of crofts in Aberdeen primarily in the 16th century.
Heather Black initially found out about the project through the Aberdeen memories Facebook page and got involved transcribing part of the Aberdeen harbour logbooks; specifically the names, registered countries, the name of the captain and what cargo was being shipped.
Having a keen interest in local history the project immediately drew her attention, and when asked about her thoughts on the event, she stated that “It was a good distraction while being on furlough from my work at the time, and very interesting too”, and is looking to participate in future events that catch her interest.
Sheila Watt was similarly involved in this project, and despite not having too much interest initially ended up having a great experience. Her daughter joined Code the City after looking for a volunteering project to take part in for a Duke of Edinburgh Award last year. Eventually Sheila joined as well after hearing about the Aberdeen Harbour Arrivals project and due to her interest in local history ended up greatly enjoying her experience, describing it as the perfect project to keep her interested during the first lockdown last year.
Taking on the role of a volunteer transcriber, she enjoyed her experience so much that she took part again for the Returned Prisoner Project and similarly had a great time in the same role. She now regularly checks on our projects through the slack channel and will hopefully be involved in future projects.
Despite some participants being apprehensive about the tech-side of things, there are lots of ways to contribute to each event, and you’ll definitely find something that plays to your strengths and skills. If you’re interested in any of the event topics you’ll find the work engaging too, and get to talk to some friendly like-minded people.
Check this post to learn more about the Harbour archival process as well as the wider project.
Our next event is CTC24 Open in Practice where we will have several projects that will appeal to non-coders, offering the opportunity to gather more data and open it up for public benefit.
In part oneof this blog post we explained the rationale of opening up the data from the Register of Returned Convicts of Aberdeen (1869-1939) . In this second part our intern for the summer project, Sara Mazzoli, explains our methodology and our results.
How we did it
Preparatory work: designing the Google Sheets
Having made the case to open the data we then designed a process for opening that data. We considered that Wikidata would be an ideal site to upload the records. Indeed, the data uploaded on Wikidata falls under the CC0 license, which allows individuals to share it and use it freely. Moreover, Wikidata allows individuals to freely query the data, and to apply visualisation and analysis techniques.
The process consisted of a few different steps, both for the opening of records and for the opening of convicts’ pictures – to which we will dedicate a separate paragraph. First, we designed two Google spreadsheets.
The first Google spreadsheet hosted the instructions for transcribing and checking the transcribed data, which we designed before the process began, as well as a table for the volunteers to sign up to either transcribe or check the records.
The other Google spreadsheet was divided into seven further sheets, one for each decade. To determine if one record pertained to one decade or the other, we took as reference the discharge date of the prisoners. Each row contained information on the transcription and checking (the person who transcribed the record; the person who checked the record; their eventual notes – e.g., outstanding information, illegible writing in the page to transcribe, etc.); link to the page of the register; page number) as well as the data of the Register’s page – which was: registered number of the convict; age on discharge; convict name and aliases; gender of the convict; complexion; eyes; hair; height (in imperial measurement); crime; sentence; sentence date; discharge date; distinguishing marks (such as tattoos, scars); address.
Once all the data was transcribed, we took two different processes to open the convicts’ data on Wikidata and to upload the isolated mug shots on Wiki commons.
Opening the convicts’ data: upload to Wikidata
Once all the data was transcribed, we decided to create another Google sheet, since it is easier to upload data on Wikidata through this platform. Here, we designed the look-up tables, and created formulas to translate the convicts’ details from natural language (English) to Wikidata properties and items’ codes (e.g., from “brown hair” to “P1884: Q2367101”, where “P1884” is the category for hair colour and “Q2367101” is brown).
Lookups of hair colours and QID codes
However, again, there were decisions we had to make:
Because metric measurement is more accurate and easier to understand, we designed a formula to translate the imperial measurement into metric.
Because distinguishing marks lacked a unique format, and because Wikidata needs some structure for the information that is uploaded to be machine-readable and to be queried; we decided not to upload the distinguishing marks.
As for the addresses, given that we wanted to visualize the addresses in a map, and noting all the addresses on the map would make it too cluttered, we have decided to just upload the first address for each individual.
Therefore, we created a Unique ID for all the items that we created so that they would be connected together. Also, we enriched the available information of the Register with the data collected by Phil Astley in his blog.
To upload the pictures, we created an Excel sheet to generate an automatic description for the pictures, using the available data from the register, as well as information from Phil’s blog. Once all the pictures were uploaded, we matched the picture(s) with the individual it was related to. Indeed, all Wikimedia services are related, and therefore it is easy to link a Wiki Commons image with a Wikidata item.
What we found out: results
Analysis of sentences: general
For the following visualizations, since they do not report the name of the convicts, we decided to make use of all the available data -, it was effectively possible to analyse the data from 278 records.
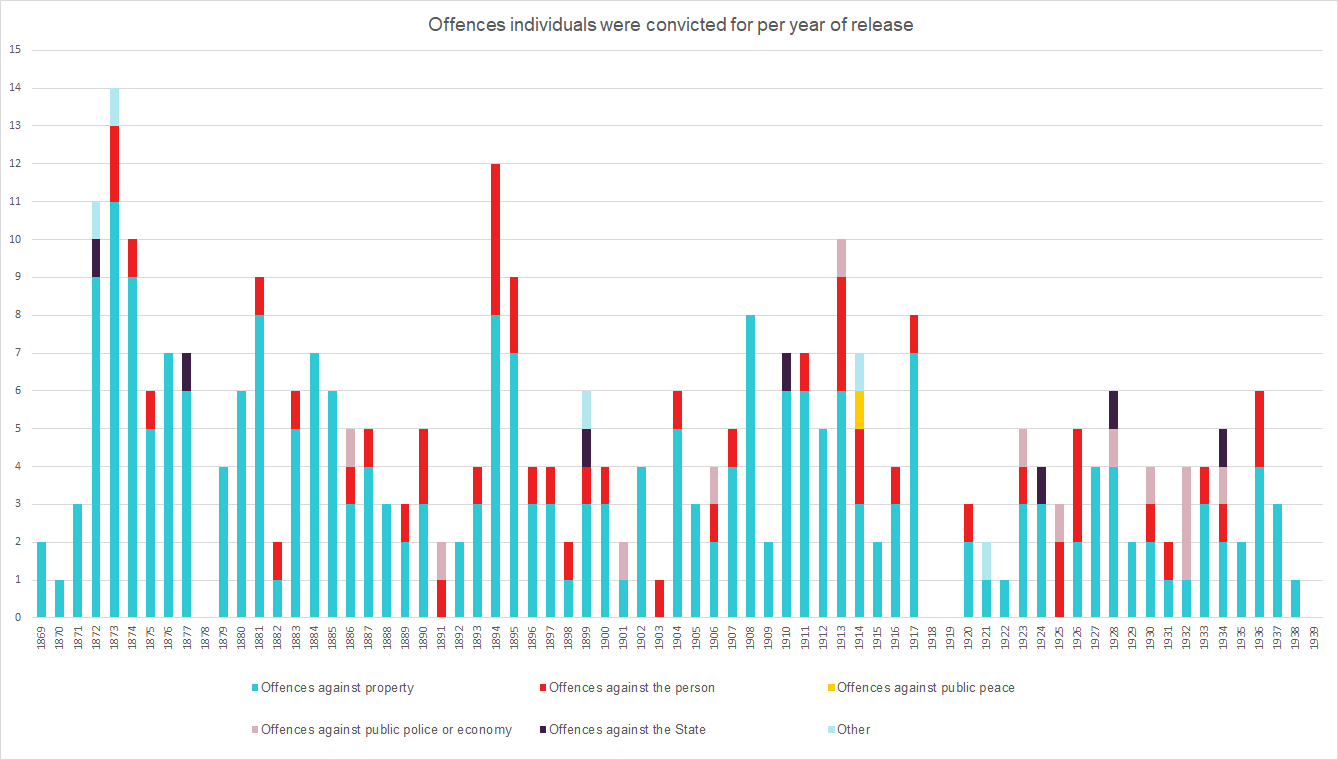
The graph below represents the number of convicts discharged every single year. Amongst these, it seems to us that there are 20 individuals who were probably sentenced to penal servitude twice, such as Elisabeth Wilson or Baxter. For all the data analysis, we decided to take as reference the date of discharge, rather than the sentence date. The reason for this lies in the fact that the sentence date was often not stated in the Register, while the date of discharge was always present. Therefore, it allows us to carry out a more meaningful and precise analysis.
It can be seen that, after the year 1904 (the year that splits the register in half), far less individuals were released. This means that most convictions happened in the early stages of the Register’s existence – and in particular during the 1860s, 1870s and 1880s. In fact, we counted 167 released individuals between 1869 and 1904, but only 111 individuals being released after 1904.
Another interesting feature, that can be seen here, is that no individuals were released in 1918 and 1919, as the Great War was raging.
If we look closer at the convictions, it is noticeable that all the sentences were penal servitudes (apart from one transportation, given in 1851). 83, however, are peculiar, since they included police supervision, hard labour, fortifying of license or fines.
Secondly, it is possible to see that a person could be convicted for more than one crime. For example, nine people were convicted for robbery and assault – that is why the number of offences is higher than the number of returned convicts, as it can be seen from the graph below. Moreover, each sentence could include “P.Cs” (i. e., previous convictions) and/or “hab & rep” (i. e., habit and repute – check the first blog post for more details).
Finally, three of the sentences given in the register were of penal servitude for life. All these three were given at the start of the twentieth century, and two of them were for crimes against the person (culpable homicide and murder). The third one was for attempting to “communicate information respecting H.M.Forces with the intention of assisting the enemy”. However, all these individuals were ultimately released within 1914 and 1931.
Because these sentences were given in the nineteenth and twentieth centuries, they did not respond to nowadays crime categories as much. For example, convictions of “abortion”, “sodomy” or “plagium” were hard to classify. Therefore, we decided to follow a classification of the time, first developed by Hume in 1797. Indeed, Hume wrote a very comprehensive work on the classification and cases within Scots Law, which better represents the crimes present in the register.
Categories:
Offences present in the Register pertaining to each category:
Offences against property
Theft (which can be aggravated by: habit and repute, housebreaking, shopbreaking, warehouse breaking), theft by opening lockfast places, embezzlement, plagium, larceny; reset; falsehood and fraud
Incest, bigamy, sodomy, indecency, removing a body from its grave
Offences against the State
Forgery of notes, uttering, Attempt to communicate information respecting H.M.Forces with the intention of assisting the enemy
Table 1: Offences as classified by Hume in 1797 (Hume, 1819). It is really fascinating to find out that plagium, which is still defined as a crime of “child stealing”, is classified as an offence against property; the rationale being that “the creature taken, which has no will on its own, is a thing” (Hume, 1819, p. 82).
Of course, this classification cannot be employed uncritically, as it reflects a view of the world on crime, justice, morality and human nature. Grasping this view of the world is impossible for us, but it is interesting to reflect on it and the impacts that it may still hold on the way we see and experience crime. Therefore, in suggesting that the offences in the Register are classified according to these categories, we do not aim to justify these classifications; but rather to frame those offences in the moral and social paradigms in which they belong to. As claimed by Pauw (2014, p. 9), “Crime history can provide insight into the social response to crime. In terms of social history, the study of crime provides perspective on society’s definition and expectations for moral behavior”. From this point of view, the category of “Offences against public police or economy” is quite exemplary. In fact, it comprehended all offences that went against “propriety, good neighbourhood and good manners”.
Therefore, as we also stressed in the first blogpost, it is important to underline that such classifications, despite having real effects on individuals, are constructed – and thus can and must be framed and questioned.
Taking a closer look at the offences for which individuals were convicted, it is evident that the vast majority were accused of crimes against
Property. The total number of offences against property were 246. In comparison, the number of offences against the person was just 50, and those against public police or economy were 12. The offences pertaining to the other two classes of crimes, summed together, account for less than 10 crimes. There were moreover a few sentences that we could not classify, such as “Military striking a superior officer”.
It is interesting to notice that, while most offences for other categories seem quite scattered through the register, most of convictions against public police or economy were mainly given within the last few years of the Register’s existence.
Analysis of sentences: averages and medians
With the aim of understanding how the sentences length changed over the decades, to understand if we could find out any particular pattern; we calculated the average sentence length given for each crime category, both before 1904 and after 1904. This is because the data on charges for crimes against property is the only one which allows a more granular and detailed analysis and confrontation of sentences from decade to decade.
Due to the fact that, as mentioned above, 84 sentences were containing other pieces of information (such as hard labour, police supervision, etc.), these sentences could not be included in the calculation of the average. Also, in this case, as for the mixed sentences, such as the above-mentioned “Assault & Robbery”, we could not determine whether the sentence length could be equally splitted between the two charges, and therefore decided to pair them together with “Other” in this analysis.
Point in time
Against property
Against the person
Against public peace
Against public police or economy
Against the State
Other and mixed sentences
Convicts released before 1904
Number of sentences per type of crime
109
17
–
3
2
12
Average sentence length (years)
6.55
7.94
–
8.33
6.5
6.33
Median sentence length (years)
7
7
–
5
6.5
5
Convicts released after 1904
Number of sentences per type of crime
64
16
1
10
2
7
Average sentence length (years)
4.57
7.5
3
4.4
12.5
5.71
Median sentence length (years)
5
5
3
4
12.5
5
Table 2: statistics on sentence length for each class of crimes, divided by point in time.
In general, sentence length for individuals released after 1904 was a bit lower compared to the penalty received by individuals released before. Calculating the average sentence length for the sentences given before 1904 (where it was possible to calculate it), we found out that convicts were, on average, sentenced to 6.73 years in prison. After 1904, that number reduced to 5.26 years. It seems that most of it has to do with shorter punishments for crimes against property, which were the vast majority and which average length for crimes against property significantly decreased for individuals released after 1904.
For crimes against the person after 1904, we see an average sentence length of 7.81 years, contrasted by a median length of 5. For convicts released before 1904 who committed a crime against the person, usually a sentence of 5 years or more was given, and thus sentences were more homogeneous – and therefore, median and average are similar. Instead, for those convicted of crime against the person released after 1904, there were four harsher sentences to 10 years or more (including the two penal servitudes for life, which lasted 15 and 30 years), and eleven sentences that lasted 5 years or less. A similar thing is true for crimes against public police or economy before 1904; where amongst those three sentences given, two were 5 years long and one, for incest, 15 years long.
Analysis of gender and age data
Amongst these 278 records that we could analyse, we found out that 37 convicts were women. Most of them were convicted for crimes against property, mostly theft. There were four however, who were convicted for a crime against the person – all of them for culpable homicide in 1886, 1893, 1923, 1929. When analysing the data for gender, it is apparent that most of women were convicted in the second half of the nineteenth century, being most of them discharged between 1869 and 1893.
In terms of how the average age of female convicts compares to male convicts, as well as to how the average sentence length given to women compares with that of male convicts; there are no apparent significant differences.
Point in time
Average age on discharge
Average sentence
Female
Male
Female
Male
Convicts released before 1904
44
39
7.5
7.03
Convicts released after 1904
39
40
3.67
5.17
Table 3: statistics on sentence length and age, divided by gender and by point in time.
Analysis of addresses data
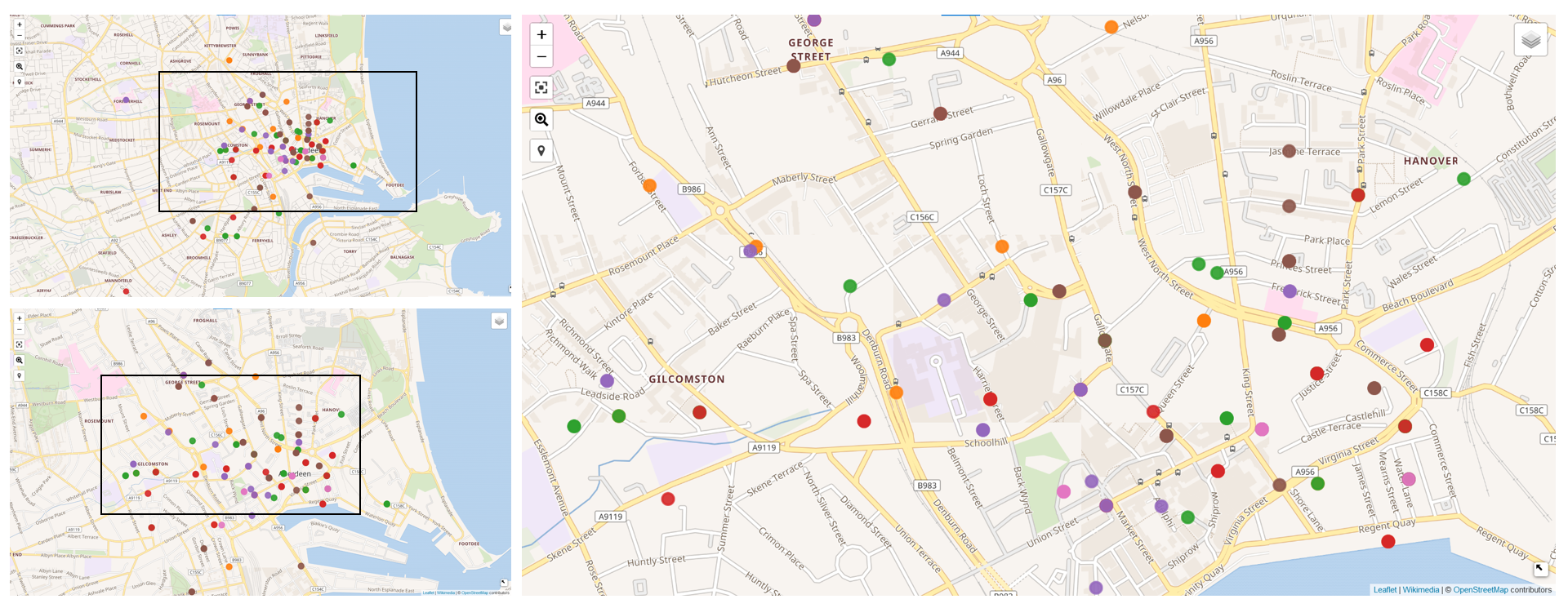
The map with the addresses was developed by Ian, and can be seen here. This visualization was created through the Wikidata queries service, and is based on the data we have currently uploaded on Wikidata. Thus, it is based on records of individuals discharged between 1869 and 1921.
Fig 1: Map with the addresses to which convicts returned. The first view on the right comprehends the whole Aberdeen urban area, while the second one below it is more focussed on the city (the represented area is that inside the black square in the first picture). The third represents Aberdeen’s city centre, where most convicts returned to (the represented area is that inside the black square in the second picture).
The yellow dots represent the address of convicts released in 1870s, the green ones is for the addresses of those who were released in 1880s, the red ones are for the addresses of those who were released in 1890s, the purple ones is for the addresses of those who were released in 1900s, the brown ones are for the addresses of those who were released in 1910s, the pink ones are for the addresses of those who were released in 1920s.
According to Smith (2000, p. 22), in 1708 Aberdeen had 5000 inhabitants. By 1800, that figure quintupled, but the city’s borders remained unchanged: “the boundaries at the time were defined by the Denburn Valley to the west, the south end of the Spital (now St Peter Street) to the north, and the tidal estuary of the River Dee to the south. […] This growth [in population] had been accommodated primarily by the infill of open space thus greatly increasing the density of the urban population”. Therefore, Aberdeen’s council decided on a plan to expand the city towards the Western areas of the Denburn valley, thereby building Union Street – which project started in 1799.
The construction of Union Street redefined the geography and the social composition of the city. While at the start of the nineteenth century, the poor and the rich more or less shared the same urban space; with the expansion of the city towards the West, the middle and upper classes moved to the newly built suburbs. The working class was thus left to live in the city centre, often in squalid and unsanitary conditions, in slum-like housing. Indeed, despite the economic prosperity experienced by the city during the second half of the nineteenth century, the living condition of the working class did not improve (Williams, 2000).
In fact, according to Williams (2000), despite the widespread poverty amongst the working classes, caused by low wages, the local government hardly ever intervened before the twentieth century. Indeed, in Victorian times, poverty was generally seen as a choice, rather than the result of social forces; and thus public intervention was not seen as a possible solution. The Victoria Lodging-House, in which 19 convicts resided as their first address – previously a residence known as Provost Skene – was opened as a result of philanthropic action, rather than from governmental initiative. The first municipal attempts to solve the housing crisis and to clear the slums are to be found at the very end of the nineteenth century and at the start of the twentieth, with the appointment of Matthew Hay as the medical officer of health. Hay denounced the conditions in which the poor lived, and suggested improving the most critical areas for the general public health interest. Therefore, the government built the Corporation Lodging House in East North street in 1899, where 17 convicts resided as their first address. It also started closing uninhabitable dwellings. More systematic attempts to overcome the indigent conditions in which the poor lived started in the Twenties, in which, for example, Guestrow was cleared. In total, the people in the Register that lived in Guestrow as their first address were 31, with the last moving there in 1913.
The high concentration of former convicts in the areas of Castlehill and Castlegate therefore may suggest that most of them lived in such conditions, and were belonging to the working class. Therefore, they might have lived in conditions of extreme poverty. This could also explain why the rate of crimes against property, which patterns usually change according to the economic cycle, remained quite high during the second half of the nineteenth century; despite Aberdeen’s economy increasing during that period.
Reflections on the project
All in all, this project has been incredibly interesting and stimulating. It represented a chance to dive into the history of Aberdeen, explore social Victorian practices, and understand and work with a platform such as Wikidata. Indeed, it was fascinating to see, for example, the way in which convicts were described. We could notice the widespread presence of tattoos, and even the presence of vaccination marks after the 1880s.
Part of the reason why the project was so stimulating, and represented an occasion to learn so much, lies in the complexity of the project itself. We had to make decisions at every stage of the project, we had to design spreadsheets and formulas, and employ tools which we had never before – and that required quite a bit of trial and error. To me, it was an occasion to understand how Wikidata, a platform born in 2012, works, and what are its potentials.
Since its foundation, Wikidata has since grown with projects like this one. In fact, as Ian told me, the project has been a great occasion to also help shape and change Wikidata’s way to categorize convictions. Indeed, the way in which data can be stored in the platform is quite flexible and fairly easy to change.
Many scholars, activists and Wikimedians have highlighted the possibilities unfolded by the opening data using Wikidata. For example, Evans (2017) has claimed that Wikidata can provide better access to datasets, and can better connect collections together. In fact, being just one platform, it potentially allows for the datasets’ items to be linked also with other items in other datasets. Therefore, Wikidata can be defined as a platform to publish linked open data (LOD), and as such can provide us with more insights on the data compared to a single institution’s website (Allison-Cassin & Scott, 2018) – since that website probably does not offer the same possibility of linking the institution’s data with that of other institutions.
Furthermore, as Ian explained to me, employing Wikidata is free, and thus far less costly than maintaining an institution’s website on which to open the data. Indeed, there is a very small risk of Wikidata being closed, as it is with any site, but the datasets on the platform can always be downloaded and backed up, and this risk is much lower than a project website set up by a local authority whose funding may be cut in future. Therefore, Wikidata can potentially represent a great opportunity for the GLAM sector, which data is so crucial to understand the history of the places where we live in. Of course, I would argue that this data must be framed and contextualized, and the choices that were made must also be made as transparent as possible. Also, it is noticeable that there are limits to which data can be opened, and how. Since the data to be opened still requires some uniform formatting, it was not possible for us to open the distinguishing marks yet. Nonetheless, for the GLAM sector Wikidata can represent an occasion to engage with the local community, and to co-create meaningful projects.
Ultimately, on this note, we want to thank once again the volunteers who took some time to help us with the project. We couldn’t have done it without your kind collaboration.
References
Allison-Cassin, S., & Scott, D. (2018). Wikidata: a platform for your library’s linked open data. Code4Lib Journal, (40).
Evans, J. [Wikimedian in Residence – University of Edinburgh]. (2017, November 7). Wikidata loves Galleries. Libraries, Archives & Museums – Jason Evans, National Library of Wales [Video]. YouTube. https://www.youtube.com/watch?v=qf6OG2QTvT4&t=1406s
Hume, D. (1819). Commentaries on the Law of Scotland, Vol. 1
Pauw, E. (2014). Reports of Criminality: The Aberdeen Journal and the Presentation of Crime, 1845-1850 (Doctoral dissertation).
Smith, J. S. (2000). The Growth of the City. In Aberdeen, 1800-2000: A New History (pp. 22-46). Tuckwell Press.
Williams, N. J. (2000). Housing. In Aberdeen, 1800-2000: A New History (pp. 295-322). Tuckwell Press.
A guest blog-post by Sara Mazzoli, a post-graduate student at Edinburgh University, who has been interning at Code The City for the last three months. During this project she has worked closely with us and with the Aberdeen City and Aberdeenshire Archives.
Introduction: what is the Register of Returned Convicts?
Historical context, use and description
The Register of Returned Convicts of Aberdeen (1869-1939) is a fascinating, “small-but-chunky” (Astley, 2021) volume contained in the Aberdeen and Aberdeenshire Archives, comprising a total of 279 entries. It is located in the Grampian police collection of the Archives. Out of these entries, about sixty feature mug shots – which can be seen here.
As suggested by the register’s title, the register was used to take note of convicts’ addresses upon release. In fact, Phil Astley – Aberdeen’s Archivist – explained to us that this register contains information on convicts that were sentenced to Penal Servitude (often noted in the register as P.S.).
The Penal Servitude Act, enforced in 1857, was meant to substitute transportation with a prison sentence. This specific sentence consisted of three parts: solitary confinement; labour and release on licence. This latter element meant that individuals sentenced to P.S. had to report monthly to the police during their licence time. Also, they had to report any change in address within 48 hours.
A typical page of the Register looks like this:
As it can be seen, at the top of each page of the register, information was noted on convicts’ physical traits and age upon release, as well as conviction and sentence. In the “Marks” section, anything noteworthy – such as tattoos, scars, deformities and moles – was written down. In fact, according to Phil Astley the industrialisation process determined a high incidence of accidents in factories. Therefore, disfigurements were common amongst workers.
At the bottom half of the page, the register featured information on the convicts’ addresses after their sentence ended. Most of the addresses of the people noted in the register were in Aberdeen. However, some also moved to nearby towns and villages – such as Dundee – or to bigger cities, such as Edinburgh and Glasgow.
Moreover, Phil suggested that there are other two particular acts that shaped the register.
The Habitual Offenders Act 1869.
The Prevention of Crimes Act of 1871. This act
Simply put, these two acts tightened former criminals’ liberties, and enhanced police monitoring of these individuals. These laws were in fact especially crafted to fight habitual criminals (Radzinowicz and Hood, 1980): with increasing urbanization, authorities were concerned with what they labelled as “criminal classes”, an expression by which they referred to individuals who mainly lived through criminal activities. The Register can ultimately be understood as an example of the attempt to monitor the movements of these repeat offenders.
The mugshots and the “habitual criminal”
The camera was developed in the first half of the Nineteenth century, and was initially seen as a tool to represent bodies in a realistic manner. Indeed, photography was depicted as an objective and neutral representation of reality, and therefore authorities started using this tool for law enforcement since the 1840s: “Given its material features and its cultural value as an objective form of representation, the camera provided the perfect tool for the documentation, classification, and regulation of the body within the carceral network” (Finn, 2009, p. 29).
Indeed, at first, as the concept of “mug shot” was developing, photos of individuals in the Register lacked a unique formatting, which started to appear in the 1890s. Indeed, as claimed by Finn (2009), mug shots developed from the Nineteenth-century portrait. These portraits featured an individual sitting, with no facial expression, and were usually taken from the front. As it can be seen, the first few mug shots look more like portraits compared to the later ones. For example:
Fig 1: two mug shots from the Register of the Returned Convicts (1869-1939). The first one, depicts Ann Mc Govern, released in 1872. The second one is the mug shot of John Proctor, discharged in 1893.
According to Holligan and Maitra (2018, p. 173), mug shots were established and developed in a milieu of “pessimism about classes of society”. Moreover, the development of criminal anthropology led to a more wide-spread use of photography in carceral settings. Scholars of this field of studies, such as Cesare Lombroso, believed that certain physical characteristics could yield the identification of criminals. The believed objectivity of photography meant that mug shots could further inform these studies; as characteristics found in mugshots could be analysed by criminal anthropologists. At the same time, the popularity of criminal anthropology led this field of studies also to shape law enforcement practices; first and foremost, by shaping the practices of mug shots taking and of noting distinguishing marks.
Specifically, mug shots were introduced in the UK thanks to the above-mentioned Prevention of Crimes Act of 1871: “Under the section 7 of the Prevention of Crime Act 1871 it was recommended that convicted prisoners be photographed before release, full and side face,measurements in millimetres and feet and inches to be made of length and width of head, and lengths of arms,feet and left middle finger including the papillary ridges of the ten fingers as well as distinctive marks by position on body” (Holligan & Maitra, 2018, p. 177). Indeed, Holligan and Maitra (2018) contend that the development of criminal anthropology led to the belief that “habitual criminals” could be identified by some specific marks; such as the length of imbs. Some of these marks were collected and published by the British Registry of Distinctive Marks, which regulated and influenced the ways in which authorities saw and noted distinguishing marks on prisoners.
Ultimately, we aim to argue that this Victorian construction of crime and of the criminal influenced the way in which the register is composed as well, and that the meaning of “crime” and “criminal” are dictated by moral and social standards. Indeed, many were arrested due to charges of Theft “Habit & Repute” which, according to Dr. Darby, means considering someone’s as having a “bad character, a bad name for theft specifically, and that other witnesses considered him a bad person”. Analysing the register means considering those social rules that shaped the way in which the register is written.
It is in our opinion fundamental to acknowledge such dimensions of the register as we open its data. It is in fact important to recognize that “Registers are political” (Ziegler, 2020), and that therefore the categories of the register are constructed. However, it must also be acknowledged that their construction does not make these categories any less impactful on individuals’ lives. Indeed, this is why we embrace attempts such as that of Phil, who tried to retrieve the humanity of the individuals in the register by associating their mug shots to stories; as we shall argue in the next paragraph.
Why this project is important: how did everything start?
Phil Astley explained that the interest in the register was built up during the 2019 and 2020 Granite Noir festival exhibitions, to which the Archives provided 19th century wanted posters, photos of 1930s crime scenes, as well as mug shots contained in the Register.
Indeed, the mug shots had attracted a positive response, and Phil started the Criminal Portraits blog, in which he started exploring the stories of returned convicts whose mug shots are contained in the register. Therefore, Phil has published more than 50 blog posts, drawing on heterogeneous sources, such as newspapers of the time and censuses. The blog has attracted more than 20 thousand views.
In discussing the plans for this project with Phil and Ian Watt of Code The City we agreed that opening up the data contained in the register – making it available as Open Data – would have social and other benefits.
According to the Open Data Handbook, open data is data that can be easily available and re-usable by anyone. There are many values pertaining to open data. Indeed, it can allow for more transparency, and therefore institutions’ or organizations’ accountability. Moreover, it can also prompt economic participation and investment by private companies. Finally, open data can enable citizen participation and engagement, as it is with this project.
In this specific case, we decided to open data from the register precisely because of the public interest it attracted. Not only is the life of the individuals contained in the register fascinating in itself, but we would argue that opening up this data has also a greater social value. For example, it would allow for individuals with a genealogical interest to find out more about their possible ancestors; or it could be useful for researchers who are carrying out their work on criminality in Scotland.
In any case, opening up data from the Archives could lead to more interest towards their rich collections, as well as to a more thorough understanding of these collections’ communal utility.
It was agreed that we would use Wikidata as the place to host the data, given Code The City’s and Ian’s knowledge of, and enthusiasm, for this platform.
How we made the data available
In the second part of this blog we will detail how we transcribed the data, prepared it for Wikidata, uploaded it in bulk, published mugshot photos and linked those.
Finn, J. M. (2009). Capturing the criminal image: From mug shot to surveillance society. U of Minnesota Press.
McLean, R., Maitra, D. E. V., & Holligan, C. (2017). Voices of quiet desistance in UK prisons: Exploring emergence of new identities under desistance constraint. The Howard journal of crime and justice, 56(4), 437-453
Open Knowledge Foundation. (n.d.). Open Definition: Defining Open in Open Data, Open Content and Open Knowledge. Retrieved from Open Knowledge Foundation: https://opendefinition.org/od/2.1/en/
Radzinowicz, L., & Hood, R. (1980). Incapacitating the habitual criminal: The English experience. Michigan Law Review, 78(8), 1305-1389.
Ziegler, S. L. (2020). Open Data in Cultural Heritage Institutions: Can We Be Better Than Data Brokers?. Digital Humanities Quarterl, 14(2).
After such a successful weekend at CTC19, we were delighted to be back for CTC20 to continue work on the Aberdeen Harbour Arrivals project. As expected, the team working on the project was made up of both avid coders and history enthusiasts which brings a great range of skills and knowledge to the weekend.
A second spreadsheet was created to input adjustments, this allowed us to clean data to be more presentable whilst keeping the accurate ledger transcriptions intact; a must when dealing with archival material. This data cleaning has allowed us to create a more presentable website which is easier to understand and navigate.
Expanding the data set
The adjustments spreadsheet also included the addition of a new column of information sourced externally from the original transcription documents. When first registered fishing vessels were assigned a Fishing Port Registration Number. Where known, that number has been added and will hopefully allow us to cross reference this vessels with other sources at some point in the future.
Vessel types and roles
Initial steps were taken to begin to create a better understanding about the various vessels, their history and purpose. Many of the vessel names contain prefixes relating to their type (e.g. HMS – His Majesty’s Ship for a regular naval vessel, HMSS for a submarine) and they have now been extracted and a list of definitions is being built up. Decoding these prefixes highlighted just how much naval military activity was taking place around Aberdeen during the First World War.
Visualising the data
Some of the team also looked forward to consider how the data could be used in the future. A series of graphs and charts have been created to highlight patterns such as most frequent ships and most popular cargo. We even have an interactive map to show where the in the world the ships were arriving from.
As with CTC19, the weekend has been a great success. Archivists learned more about data and the coders benefitted from over 15,000 records to play with.
Next steps
An ideal future step for the project is the creation of individual records in the website for each vessel so we can begin to expand on the information – i.e. vessel name, history of Masters, expanded description about what it was, what role in played in the First World War. Given the heavy use of Wikidata by many of the other projects that were part of CTC19 and CTC20, consideration has to be given to using Wikidata as the expanded repository for building up the bigger picture for each vessel. However, as we are still very much in the historical investigation stage and not entirely sure about the full facts for many vessels it would not be appropriate at this stage to start pushing unverified information into Wikidata.
The arrivals transcription project is an ongoing partnership between Code the City and Aberdeen City & Aberdeenshire Archives. It forms part of a wider project funded by the Archives Revealed initiative funded by The National Archives which aims to improve the accessibility of records.
The arrival registers are a small part of a much larger collection which was transferred to Aberdeen City and Aberdeenshire Archives as a result of a partnership with the Aberdeen Harbour Board.
The project was originally intended to be part of the physical Code the City 19 event in April 2020 but in anticipation of the nationwide restrictions, it was decided to move entirely online. In the week before we were told to work from home, Mollie photographed each individual page (all 649 of them) from the arrival registers from 1914-1920 and uploaded them to the Google Sheets system which had been set up by Ian. This meant that we had a large amount of material which could be worked on for an extended period.
After creating a set of guidelines and helpful links, we invited the public to work on transcribing and checking entries from March 27th onwards. As the online CTC19 event was scheduled for 11-12th April this allowed us two weeks to create enough data to be useful to the coders over the official weekend.
Transcribers accessed two Google sheets. The first was to log their participation and note what photograph they were transcribing.
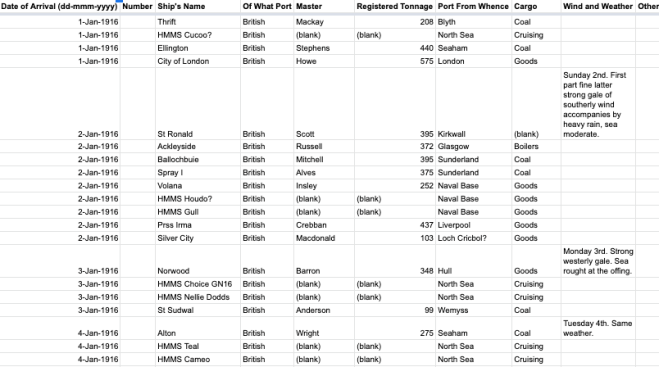
The second sheet was the one into which they transcribed the data.
Example of 1916 transcription
We also set up an open Slack group where transcribers could chat, ask questions, get help etc.
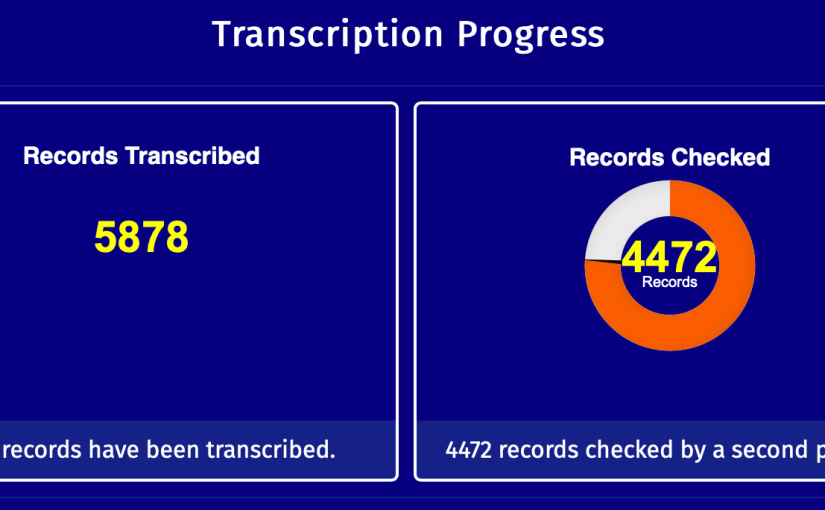
Progress was rapid: by the end of the weekend almost 4,000 records had been transcribed and checked. At the time of writing (2nd May 2020) that has now grown to over 7,000 records transcribed.
When an image has been transcribed, and checked, we lock off the entries to preserve them form change.
The data which had been transcribed was used to create a website, set up by Andrew Sage of CTC, where we could see information in a collated an organised way – this was extremely useful to inform other transcriptions. So far we have managed to fully complete 1914 and are working through the rest of the years.
The arrivals transcription project started as a great way to highlight an important time in the history of the Harbour, which has always been a big part of Aberdeen. However, given current circumstances, it has also become a great opportunity to give people something to focus on.
The project remains open – and you can still get involved by contributing just an hour or two of your time. Start here.