We’ve created a review of the last year, and a look ahead to some exciting plans for 2024.
You can read more in our latest newsletter.
See you all in 2024.
Code The City is a civic hacking initiative focused on using tech and (open) data for civic good. We use hack weekends, open data, workshops, and idea generation tools. We run Data Meetups, the Aberdeen Python User Group and the annual Scottish Open Data Unconference
We’ve created a review of the last year, and a look ahead to some exciting plans for 2024.
You can read more in our latest newsletter.
See you all in 2024.
When we edit Wikidata we often come across duplicates. These can be caused by ingestion scripts running without checks, or editors adding items without investigating whether another item for the same entity already exists.
Of course, there will also be items with the same or similar labels (or names) which identify different things. Think apple and Apple, or indeed Apple. But in this case we are speaking about the same ‘thing’.
At the time of writing we have three Wikidata items for Marine Scotland. That is three items with their own QID each of which claims to be for the same entity.
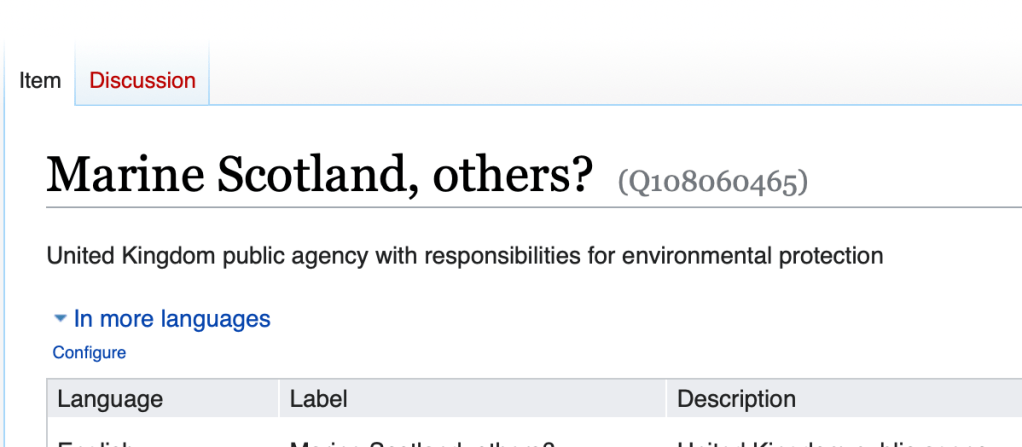

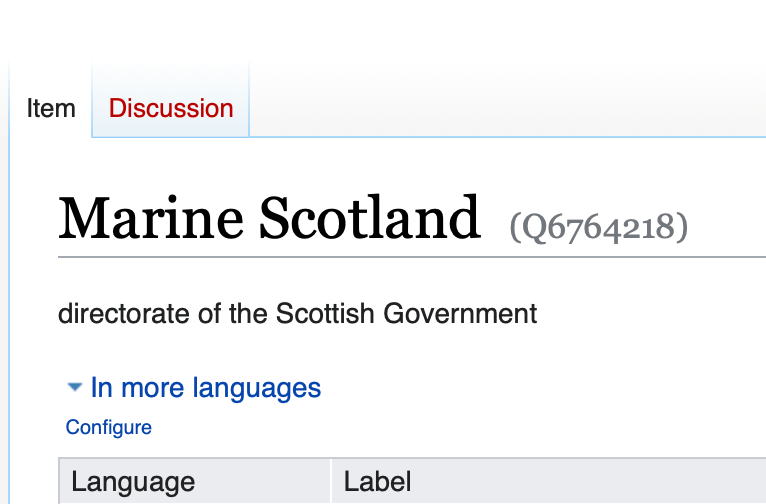
Of course, by the time you read this blog post these three will now be one. So how do we do that?
We don’t generally delete wikidata items, since other items may point to them. What we would generally do, including in a case like this is merge them into one. By doing so redirects are put in place, meaning that any other items pointing to any of these three will point to the new merged site.
To merge items we need an extension called ‘Merge’. To obtain it click on the Preferences tab at the right of the wikidata page.

Then click on Gadgets on the ribbon menu.

Finally click on the check box next to Merge, under the Wikidata-centric heading.

Don’t forget to save your changes. You will be returned to the Wikidata item. You may need to refresh the page. Hover over the More link to the left of the search box at the top right of the page. You should see something like this with two drop-down options:

You’re now all set.
Open the items in separate tabs, or note the QIDs of the two (or more) items that require merging. I usually copy the QIDs to a text editor so I can retrieve them without retyping. I’ll grab the QID of the ‘best’ item, then go to the less good item. On the latter, click on Merge with.
You’ll get this dialogue box.
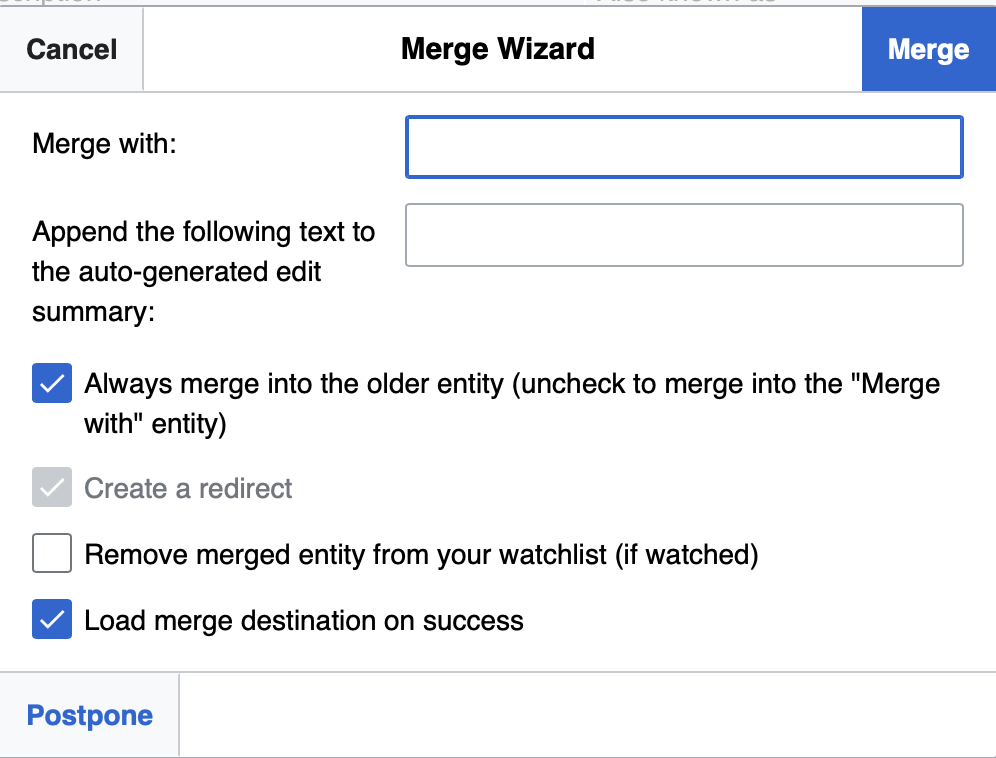
Enter the QID of the best one into the Merge with text field, and you uncheck the “Always merge into the older entity”. The latter is the default and depending on the result you want, you can end up with the QID of the newer, or inferior, item being used. It’s not critical, as we will see.
Click the blue Merge link (top right of the dialogue box) when you are ready.
The two items will now be merged into one, which will be loaded on screen. All links to that item will continue to work, and all to the now vanished item will point to the sole existing item instead,
If you have a third item repeat the process until you have one item left.
You may need to do a little tidying when you have completed merging. Carefully examine the new item – labels, descriptions and aliases in particular. But also check for duplicates, or even competing claims in other fields. Resolve these as well as you can.
You’ve now completed merging, and have provided a valuable service to to other Wikidata users!
Public Sector Information (PSI) is information that has been created by Public Bodies. In 2003 The EU published “Directive 2003/98/EC on the re-use of public sector information, known as the PSI Directive. This is an EU directive that stipulates minimum requirements for EU member states regarding making public sector information available for re-use. This directive provides a common legislative framework for this area. The Directive is an attempt to remove barriers that hinder the re-use of public sector information throughout the Union.” [1]
In 2005 the UK Government introduced its own regulations. [2] And ten years later the it introduced the Reuse of Public Sector Information Regulations 2015 [3] which set out the framework for UK public sector bodies sharing information and data in line with those requirements. The National Archives produced guidance for both public bodies, and for would-be re-users of the info and data. [4]
Re-use means using public sector information for a purpose different from the one for which it was originally produced, held or disseminated.
“Public sector information constitutes a vast, diverse and valuable pool of resources. In Market Assessment of Public Sector Information (commissioned by the Department for Business Innovation and Skills in 2013), the value of public sector information to consumers, businesses and the public sector itself in 2011/12 was estimated to be approximately £1.8 billion (in 2011 prices). [5]
“Re-use of public sector information provides enormous opportunities for economic and social benefits, while also promoting transparency and accountability of the public sector.” [5]
Re-use of public sector information stimulates the development of innovative new information products and services in the UK and across Europe, thus boosting the information industry.
“The Re-use of Public Sector Information Regulations 2015 [have been] in force from 18 July 2015. They build on the prior 2005 Regulations which removed obstacles to the re-use of public sector information. The 2015 Regulations harmonise and relax the conditions of re-use for public sector information, and bring the cultural sector into scope. The 2015 Regulations continue to improve transparency, fairness and consistency among public sector bodies and re-use of their information. [6]
Public bodies, up until 2010 were obliged to make information and data available under a PSI Click-Use Licence. [7] In 2010 this was superseded by V1.0 of the Open Government Licence ( or OGL). The latter has been updated twice and is now at version 3.0. [8]
While several local authorities, The Scottish Government and a few government agencies have published open data either on dedicated portals or in sections of their websites explicitly licensed under Open Government Licence (OGL 3), almost no organisations make website content so available for re-use despite an obligation to do so for almost 20 years.
When I worked at Aberdeen City Council, trying to get senior managers in numerous services and departments to make information and data available under OGL or its predecessor was a non-starter. The legal department at the time didn’t support it. And any conversation pushed it further down the line as a ‘nice-to-do’. And we weren’t alone. No council that I can recall was doing this as standard for their websites.
The one notable, and welcome exception, that I am aware of, was The Scottish Government. Since at least 2015 they’ve permitted reuse under OGL, albeit behind a Crown Copyright link at the foot of each website page. But Since April 2022 they explicitly had an open licence statement on each page. Unfortunately this doesn’t carry through to other public body sites, at least not explicitly. With over 180 to check [8] it is difficult to be absolutely certain.

I personally, and with various groups, have campaigned for the Scottish public sector to meet their obligations under RPSI 2015. In November 2018 I responded to the consultation on the Scotland Draft Action Plan on Open Government[9]:
“There is one simple thing that could be done with immediate impact, and minimal effort, to free up large amounts of data and information for public re-use: adopt an Open Government Licence (OGL) for all published website information and data on the Scottish Government’s website(s), and other public sector sites, the only exception being where this cannot legally be done, as would be the case when personal data is involved.”
I continued:
“At present, websites operated by Scottish Government, local authorities, health boards etc. all appear to have blanket copyright statements. I certainly could find no exception to that. With OGL-licensed content, where data is not yet available as Open Data (OD), a page published as HTML could be legitimately scraped and transformed to open data by third parties as the licence would permit that. “
And
“The Scottish Government should mandate this approach not just for the whole of the public sector but also for companies performing contracts on behalf of Government, or who are in receipt of public funding or subsidy.”
In work in 2019, revisited in 2020, I looked in more detail at how local authorities in Scotland conformed to their obligations under RPSI regulations. [10] At that point 25 of 32 did not licence web content under OGL at all. Only one authority got it right, and the remainder, six authorities, had a stab at granting permission.
In March 2022 was lead author of a report for The David Hume Institute: “What is Open Data and Why Does it Matter?”[11] In that report, which set out the economic, social, environmental drivers for opening government data, I also highlighted that most councils failed to make their website data and information available for re-use under a clear licence.
Today in a Tweet, Councillor Anthony Carroll, stated “At today’s Glasgow Digital Board, a paper I’ve pushed for passed on @GlasgowCC ‘s website content to have an Open Government License. This means anyone can re-use website content (with attributation) instead of it being copyrighted”. [12] He then reference the DHI paper which I authored.
So, well done to Councillor Carroll and to Glasgow City Council.
Now we need COSLA to push all local authorities to do the same. And, as I asked in 2018 and again in 2022, for Scottish Government to compel all public bodies to fulfil their legal obligations and do this properly.
Ian Watt
10 March 2023
Header Image: http://www.nationalarchives.gov.uk/information-management/government-licensing/ogl-symbol.htm
This page contains quoted text from government pages which are licensed under the Open Government Licence, and a Wikipedia page which is licensed as CC-BY-SA, all of which are referenced at the foot of the article.
[Edited for clarity 11 March 2023]
As the year draws to a close, and we start to make plans for next year’s activity, we also take the opportunity look backwards over the current year. This has seen us move from wholly online events, due to the pandemic, back to physical – or rather hybrid – sessions. In addition to our statutory report to OSCR which we will file soon, we also want to look at what our community has achieved over the year.
It’s clear to us, as it has been since our inception in 2014, that the success of our activity is at least as much attributable to those who attend and give their time as it is to our board’s oversight and leadership. We can run as many events as we are comfortable with but unless our supporters turn out, get involved, participate in activities and support each other, the impact will be minimal. That’s why as we recover from the pandemic and enforced distance from each other, it’s essential that we all make more of an effort to attend, to take part, and to donate our time, skills and knowledge to make a difference to local society.
We’re now firmly back at ONE Tech Hub (OTH) which is a great venue. We’re really grateful to Opportunity North East for the sponsorship in kind which they give by allowing us to host our events there.
We planned four events this year and ending up running three. While the numbers of attendees full justified running those three, they are well down on pre-pandemic numbers. This something we are keen to understand.
We started this year’s hack events in February with an online event. This hackathon attracted 19 people on day one and 13 on day two. They participated in four projects. The event page has links to the final presentation videos for each as well as to Github repos.
This weekend in May saw 13 attendees on Saturday and 11 on Sunday attend the sessions. The physical event was back at ONE Tech Hub. We had three initial projects reducing to two. Please see the event homepage for more details.
With 21 and 16 attendees respectively on Saturday and Sunday, this physical event felt like we were bouncing back from the pandemic. The attendees worked on four projects, which are captured in this YouTube playlist.
We had high hopes after CTC27 with numbers climbing from last year’s pandemic events and restricted attendances. But we were baffled why signups for CTC28 remained stubbornly low just a week before the event. Please let us now your views. We’d promoted it through the usual channels – Twitter, Facebook, LinkedIn, several Slack groups, Mastodon and our newsletter as well as third-party sites. With just a handful of committed participants we took the decision to postpone it to March 2023. It was also doubly disappointing as we had just secured sponsorship from Converged Communication Solutions Ltd to covering catering costs. We’re so grateful to Neil and his colleagues there. And we’ll carry that sponsorship over to the first event of 2023.
The group held nine sessions this year, all bar one of those were at OTH all with good attendee levels and varying topics from guest or member speakers. We’ve been without a sponsor all year which is eating into CTC funds as we subsidise catering costs. If you know of a local tech company who may be interested in sponsoring the event please get in touch!
The third annual Scottish Open Data Unconference took place in November. This was the first physical manifestation as both the predecessors were forced online. While the number of attendees was lower than we’d aimed for (21 on the Saturday and 16 on the Sunday) we still saw 31 sessions run over the two days. You can download a PDF of notes from all sessions. One outcome was a statement which we issued following the weekend, setting out the importance of Open Data (OD), the current state of OD in Scotland, and what civic society needs from Government and other sectors to flourish as well as it does in other countries.
The last of our formats to return post-pandemic were the ADM sessions. These are expensive to run and are heavily dependent on sponsorship to cover catering costs and more. We’re grateful to The Data Lab and ScotlandIS for their financial generosity and to ONE for their providing such as welcoming, friendly and professional space. The sessions re-started in October with the ever-popular showcase of MSc students projects over the summer, and continued for the rest of the year.
We had two changes to our board in November. Pauline Cairns who has been with us for a year stepped down with our thanks and best wishes for the future. Pauline had led some great work with RGU students and she will be missed!
We were also joined on the board by Jack Gilmore. Jack has been almost a permanent fixture at our events especially in the Open Data Scotland project which he has led with fellow-Trustee Karen Jewell. We’re looking forward to Jack’s input and energy in moving the charity on!
The Open Data Scotland project (born at a previous SODU event and developed over 4 or 5 hack weekends) saw three short-listings at the Open UK awards which took place on 31 November at the House of Lords.
The project was shortlisted in the Open Software category (against BBC R&D and another nominee!). Karen Jewell was short-listed for the Individual category for her work on ODS, and Jack Gilmore was shortlisted – and won!! – in the Young Person category. Well done, Jack and to Karen and all developers who have contributed so far to the project!
The year ahead
Thanks to all who turned out this year, got stuck into projects, volunteered to speak, or shared their enthusiasm and knowledge. You’re all heroes!
We look forward to a busy 2023. We’ll have the full complement of event formats to get involved in. We will welcome familiar faces back and new ones who come along for the first time. We couldn’t do it without you all! Have a great break over the festive season and see you in the New Year.
The third annual Scottish Open Data Unconference (SODU2022) took place in Aberdeen on 5–6 November 2022 in Aberdeen and online. Over the two days, attendees primarily from civic society, participated in 31 themed discussions. These covered diverse topics such as Open Data’s contribution to the economy; Policy, Strategy and Legislation of Open Data; The Technology behind Open Data Scotland; and The Ownership of Properties in Aberdeen City Centre. The organisers and participants wish to thank The Data Lab for their generosity in sponsoring the event, and ONE Tech Hub for providing the venue for the unconference.
The following statement was developed from the final session of the weekend. It has been collated and published on behalf of those at the unconference and in wider civic society by the organisers of the event, Code the City.
Making data (primarily government data) available under an open licence has a number of identified benefits. These may be categorised as humanitarian, social, economic, performance and environmental [1][2].
While the Scottish Government publicly accepts the value of open data, the reality is that delivery on strategy and policy lags far behind what should be delivered.
The introduction to the 2015 Open Data Strategy for Scotland [3] identifies many of the benefits and reasons for making data open. The Scottish Government’s participation in the international Open Government Partnership [4] is based on the social benefits of improving transparency and accountability, and enhancing citizen participation. The Scottish Government’s Digital Strategy 2021 [5] identifies the potential economic benefits of open data through innovation and entrepreneurship. In this context it is estimated that the value to Scotland’s economy of this, if done well, calculated as a percentage of GDP would be of the order of £2.23bn per annum.
That said, apart from some small and isolated instances of very good open data publishing in Scotland the majority of public bodies (thought to number 179 but ironically there is no central set of open data to corroborate that) including health boards, local councils, universities, government departments etc publish no, or very little open data.
It is not clear who is the lead for open data for the public sector in Scotland. Where does responsibility sit for implementation of the various strategies and plans? Whose role is it to monitor performance, report on that, or measure impact. And in each of the 179 or thereabouts public bodies, who has the responsibility to ensure that their organisation is implementing open data to deliver the multiple benefits noted above?
When open data is produced it often suffers from many issues:
However, in civic society there is a small but thriving community for open data. They have, in addition to organising and attending three annual unconferences for Open Data, built, maintained and enhanced the Open Data Scotland portal [6].This project has provided a range of opportunities beyond making what open data exists in Scotland findable for the first time. It has also shared knowledge and expertise, and encourages community participation in the development of the site.
Working with open data increases the breadth of experiences of students developers, analysts, businesses, and others, and increases opportunities. Participation in the development of projects such as Open Data Scotland continues to provide educational opportunities as well as societal benefits.
The lack of open data, provided to high standards, universally, and in a sustained manner is a barrier to innovation and a threat to transparency and accountability.
Short term data publishing projects with no longevity are a risk to business continuity for those who are dependent on it.
There is a broken feedback loop to publishers. Individuals and organisations, especially businesses, which are using open data need to be vocal about it. Otherwise, it is only natural for publishers to assume that their data is not being used, deem it to be without value, which may lead to termination of publication.
The government has created strategies and plans, but without mandate to publish for every public body. This has been shown over seven years not to work. [7]
There is a double threat to the provision of open data in Scotland. While the Scottish Government is refreshing its 2015 Open Data Strategy, the community fear that the new version will not be fully consulted on and that it will seek to water down the commitment which the Scottish Government made to data being made ‘open by default’. This would be a retrograde step and act against the intentions of the 2021 Digital Strategy and participation in the Open Government Partnership.
In addition the Retained EU Law (Revocation and Reform) Bill [8] being put before the UK parliament would sweep away the UK’s Re-use of PSI Regulations 2015 on which basis data which has not been explicitly published as open data can be sought and used. As Jeni Tennison of ODI noted “[without these regulations] and with unprecedented pressures on the public purse, public bodies will start charging for data. Services using it will become more expensive. Some will close down. Others just won’t be built.” [9] This would kill open data in Scotland and stifle delivery of the Digital Strategy 2021
We have identified that for Open Data to flourish in Scotland we need better commitment to, and engagement from, all organisations, bodies, or people with an interest in open data and the benefits it can deliver. We also have the following specific requests.
We need oversight of delivery of open data in the Scottish Government to be a specific role – not be spread over multiple roles and structures.
We need the refresh of the Open Data Strategy to be fully consulted on. It needs to strengthen, not weaken, the Scottish Government’s commitment to open data publishing. It needs to introduce regulations obliging each publicly-funded body in Scotland to deliver open data. It needs to identify a specific role in each public sector organisation which will have a responsibility for implementing the strategy.
It needs to provide a monitoring framework for ministers on progress in implementing the strategies which involve open data. This needs to be reported on publicly.
The Scottish Government needs to join with civic society in lobbying the UK government to retain R-PSI regulations and be prepared to introduce Scottish legislation to replace it if this fails.
For businesses to use open data to deliver new products and services as outlined in the Digital Strategy, businesses need reliable, regular publishing without changes. Charging for data is a barrier to innovation and needs to cease.
Anyone, including businesses, who are using open data need to be open about it. They should avoid agreeing contracts which oblige them to be silent about open data use to provide services which are only deliverable using open data. If Government is to be persuaded to make data available and keep making it available the use needs to be seen. We need businesses to join with civic society in lobbying for more, better open data.
We need Scotland’s schools, colleges and universities to use open data in their curriculum. We need teaching staff to better understand what open data is, how it can be used and to use it in course work. We need colleges and universities to publish open data which can be re-used too.
The third sector needs to engage with civic society in promoting the use and benefits of open data. They need to demand that data is published openly which they can use. They need to educate their trustees and staff about the benefits of open data – such as the use of standards and platforms including 360 Giving.[10]
We need those in the press to participate in the conversations about open data, to get involved with civil society groups, to challenge government and be involved with the broader community. We need a press which understands the potential and power of open data and to help share the case for it and stories about open data.
We need the public to understand what open data is and what it can potentially deliver. We can help by providing access to education, resources such as the Open Data Scotland portal, and success stories from using open data. Government and the education sector have a responsibility here too. We need the public to tell us about challenges and success stories.
[1] https://www.europeandataportal.eu/en/training/what-open-data
[2] https://opendatahandbook.org/guide/en/why-open-data/
[3] https://www.gov.scot/publications/open-data-strategy/
[4] https://www.gov.scot/policies/improving-public-services/open-government-partnership/
[5] https://www.gov.scot/publications/a-changing-nation-how-scotland-will-thrive-in-a-digital-world/
[7] https://codethecity.org/2019/11/15/scotlands-open-data-february-2019-an-update/
[8] https://bills.parliament.uk/bills/3340
[9] https://twitter.com/jenit/status/1576140360820330496?s=61&t=nI2hETRy_yo0zmhc13ycCg
[10] https://www.threesixtygiving.org/
Header Photo by Hannah Busing on Unsplash




