Building on our foundations
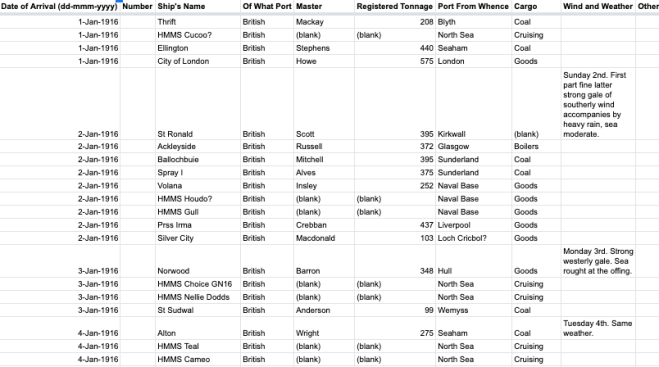
After such a successful weekend at CTC19, we were delighted to be back for CTC20 to continue work on the Aberdeen Harbour Arrivals project. As expected, the team working on the project was made up of both avid coders and history enthusiasts which brings a great range of skills and knowledge to the weekend.
A second spreadsheet was created to input adjustments, this allowed us to clean data to be more presentable whilst keeping the accurate ledger transcriptions intact; a must when dealing with archival material. This data cleaning has allowed us to create a more presentable website which is easier to understand and navigate.
Expanding the data set
The adjustments spreadsheet also included the addition of a new column of information sourced externally from the original transcription documents. When first registered fishing vessels were assigned a Fishing Port Registration Number. Where known, that number has been added and will hopefully allow us to cross reference this vessels with other sources at some point in the future.
Vessel types and roles
Initial steps were taken to begin to create a better understanding about the various vessels, their history and purpose. Many of the vessel names contain prefixes relating to their type (e.g. HMS – His Majesty’s Ship for a regular naval vessel, HMSS for a submarine) and they have now been extracted and a list of definitions is being built up. Decoding these prefixes highlighted just how much naval military activity was taking place around Aberdeen during the First World War.
Visualising the data
Some of the team also looked forward to consider how the data could be used in the future. A series of graphs and charts have been created to highlight patterns such as most frequent ships and most popular cargo. We even have an interactive map to show where the in the world the ships were arriving from.
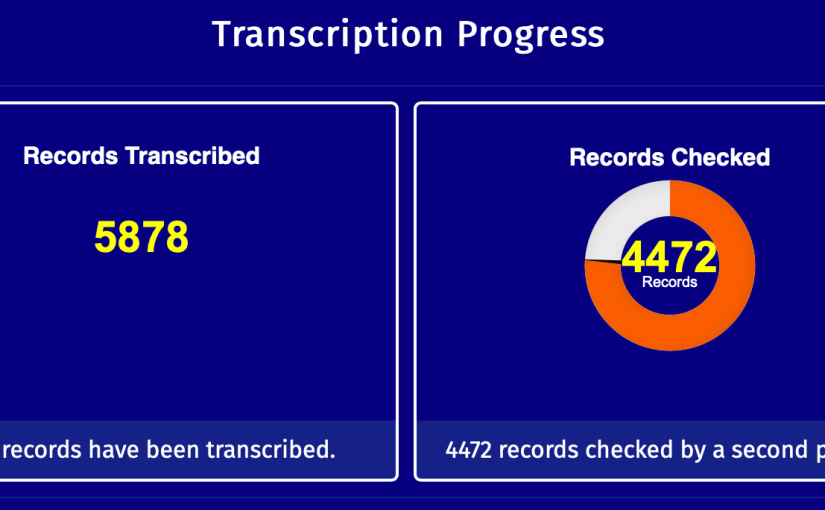
As with CTC19, the weekend has been a great success. Archivists learned more about data and the coders benefitted from over 15,000 records to play with.
Next steps
An ideal future step for the project is the creation of individual records in the website for each vessel so we can begin to expand on the information – i.e. vessel name, history of Masters, expanded description about what it was, what role in played in the First World War. Given the heavy use of Wikidata by many of the other projects that were part of CTC19 and CTC20, consideration has to be given to using Wikidata as the expanded repository for building up the bigger picture for each vessel. However, as we are still very much in the historical investigation stage and not entirely sure about the full facts for many vessels it would not be appropriate at this stage to start pushing unverified information into Wikidata.





{kind=link}