
In the run up to Code The City 19 we had several suggestions of potential projects that we could work on over the weekend. One was that we add all of the Provosts of Aberdeen to Wikidata. This appealed to me so I volunteered to work on it in a team with Wikimedia UK’s Scotland Programme Coordinator, Dr Sara Thomas, with whom I have worked on other projects.
In preparation for CTC19 I’d been reading up on the history of the City’s provosts and discovered that up to 1863 the official title was Provost, and from that point it was Lord Provost. I’d made changes to the Wikipedia page to reflect that, and I’d added an extra item to Wikidata so that we could create statements that properly reflected which position the people held.
Sara and I began by agreeing an approach and sharing resources. We made full use of Google Docs and Google Sheets.
We had two main sources of information on Provosts:
- Memorials of the Aldermen, Provosts, and Lord Provosts of Aberdeen, 1272-1895 by Munro 1897, out of copyright, scanned and made available openly, and
- Wikipedia, which I suspect draws on the former although there are date discrepancies.
Running the project
I started by setting up a Google Sheet to pull data from Wikipedia as a first attempt to import a list to work with. The importHTML function in Google Sheets is a useful way to retrieve data in list or table format.
I entered the formula in the top left cell (A1):
=importhtml("https://en.wikipedia.org/wiki/List_of_provosts_of_Aberdeen", "list", 27)
and repeating the formula for all the lists – one per century. This populated our sheet with the numerous lists of provosts.
That state didn’t last very long. The query is dynamic. The structure of the Wikipedia page was being adapted, it appeared, with extra lists – so groups of former provosts kept disappearing from our sheet.
I decided to create a list manually – copying the HTML of the Wikipedia page and running some regex find and replace commands in a text editor to leave only the text we needed, which I then pasted into sheets.
Once we had that in the Google Sheet we got to work with some formulae to clean and arrange the data. Our entries were in the form “(1410–1411) Robert Davidson” so we had to
-
- split names from dates,
- split the start dates from end dates, and
- split names into family names and given names.
Having got that working (albeit with a few odd results to manually fix) Sara identified a Chrome plugin called “Wikipedia and WikiData tools” which proved really useful. For example we could query the term in a cell e.g. “Hadden” and get back the QID of the first instance of that. And we could point another query at the QID and ask what it was an instance of. If it was Family Name, or Given Name we could use those codes and only manually look up the others. That saved quite a bit of time.
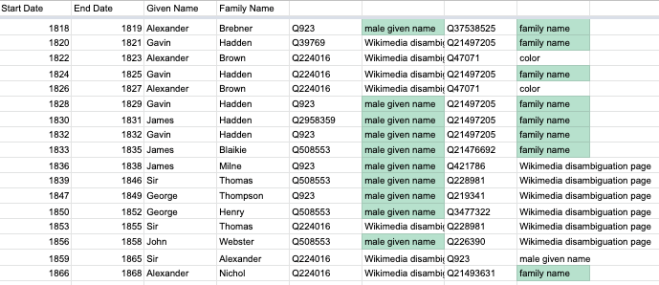
Our aim in all of this was to prepare a bulk upload to Wikidata with as little manual entry as possible. To do that Sara had identified Quickstatements, which is a bulk upload tool for Wikidata, which allows you to make large numbers of edits through a relatively simple interface.
Sara created a model for what each item in Quickstatements should contain:
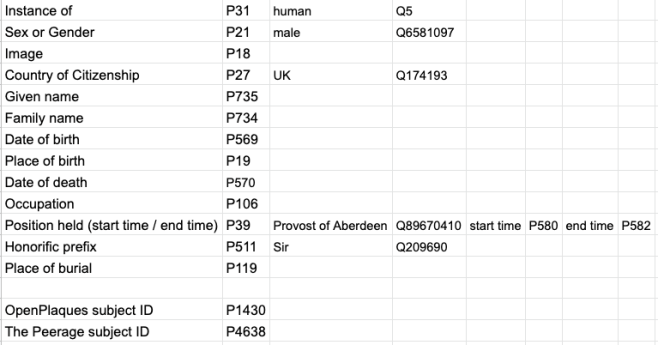
There are a few quirks – for example, how you format a date – but once you’ve got the basics down it’s an incredibly powerful tool. The help page is really very useful.
Where dates were concerned, I created a formula to look up the date in another cell then surround it with the formatting needed:
="+"&Sheet1!J99&"-00-00T00:00:00Z/9"
Which gave +1515-00-00T00:00:00Z/9 as the output.
You can also bulk-create items, which is what we did here. We found that it worked best in Firefox, after a few stumbles.
Data harvesting
As mentioned above, we used a printed source, from which we harvested the data about the individual Provosts. It’s easy to get very detailed very quickly, but we decided on a basic upload for:
- Name
- First name
- Last name
- Position held (qualified by the dates)
- Date of birth, and death (where available).
Some of our provosts held the position three or four times, often with breaks between. We attempted to work out a way to add the same role held twice with different date qualifiers, but ultimately this had to be done manually
The first upload
We made a few test batches – five or six entries to see how the process worked.

When that worked we created larger batches. We concluded the weekend with all of the Provosts and Lord Provosts being added to Wikidata which was very satisfying. We also had a list of further tasks to carry out to enhance the data. These included:
- Add multiple terms of office – now complete,
- Add statements for Replaces (P1365) and Replaced By (P1366) – partly done,
- Add honorific titles, partly done
- Add images of signatures (partly done) and portraits ( completed) from the reference book,
- Add biographical details from the book – hardly started,
- Source images for WIkiCommons from the collection portraits at AAGM – request sent,
- Add places of burial, identifiers from Find A Grave, photographs of gravestones,
- Add streets named after provosts and link them.
You can see the results in this WikiData query: https://w.wiki/PsF
This was a very interesting project to work on – and there is still more to do to improve the data, which you can help with.














