
This project, which was part of CTC20, grew from a WMUK / Archaeology Scotland join project carried out by Scottish Graduate School of Arts & Humanities intern Roberta Leotta during lockdown 2020. More details about the background to the project can be found here.
It’s often touted that there are some cities in Scotland (coughEdinburghcough) where there are more statues to animals than there are to women. In my own work transferring OpenPlaques data to Wikidata I’ve observed that there are more entries for Charles Rennie Macintosh than there for women in Glasgow. So in this light, it’s somewhat refreshing to work on a project that celebrates all kinds of memorials to women in Scotland.
The Women of Scotland: Mapping Memorials project began in 2010 as a joint project between Glasgow Women’s Library, and Women’s History Scotland. It’s similar in many ways to OpenPlaques, but using Wikidata could add an extra dimension – let’s increase the coverage of women’s history and culture on the Wikimedia projects by getting these memorials and the women they celebrate into Wikidata, use that to identify gaps in knowledge, and then work to fill the gap.
Over the two days, here’s what we did:
Data collection
We scraped the initial list of data from Mapping Memorials website manually, and created a shared worksheet based on a model that’s been used previously for other cities. (The manual process is slow, and a bit fiddly, and is the one thing that I wouldn’t do again. We’re in contact with the admin so going forward, I’m hopeful that we wouldn’t need to repeat this step in the future.)
Once we had this list, we could create a more automated process to deal with gathering the other pieces of information we needed to create new, good quality Wikidata items, although some (description, for example) needed a human eye.
Wikidata identifiers
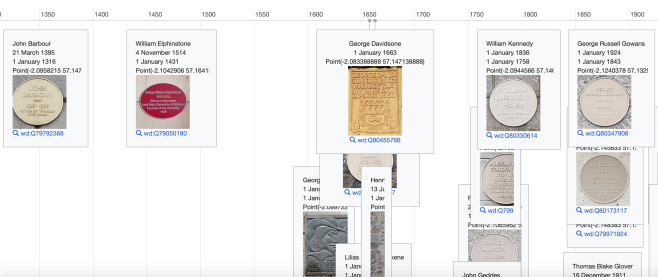
We were using two main identifiers on Wikidata – P8048 (Women of Scotland memorial ID) and P8050 (Women of Scotland subject ID). The former for the entries to the memorials themselves, and the latter for the women they celebrate. Where the women didn’t have entries, we could create those, and then link them to the entries for the memorials.
Both identifiers use the last part of the URL for each entry on the Mapping Memorials site, so that was fairly easy to do in Google docs. Once we had that info, it’s an easy enough step to bulk-create items either using Quickstatements or Wikibase CLI.
Creating items & avoiding duplicates
There’s a plug in for Google Sheets called Wikipedia and Wikidata Tools which has some useful features for projects like this – WikidataQID for looking up whether something already exists on Wikidata, and WikidataFacts, which tells you what that item is. The former is ok if you have an exact match, the latter is really useful for flagging anything which might lead to a disambiguation page, for example.
Ultimately we did end up with a few duplicates that needed to be merged, but this was pretty easily managed, and it really showed how useful it is to have local knowledge involved in local projects – there were a couple of sets of coordinates that were obviously wrong, but also some errors that wouldn’t have been spotted by someone unfamiliar with the area.
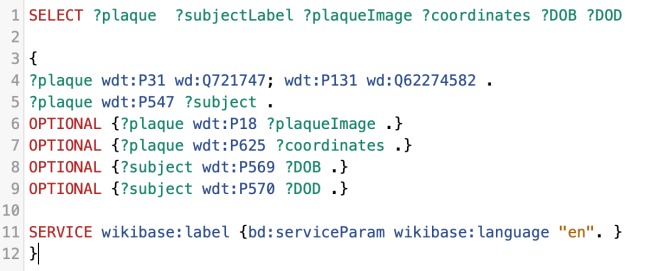
Coordinates and dates
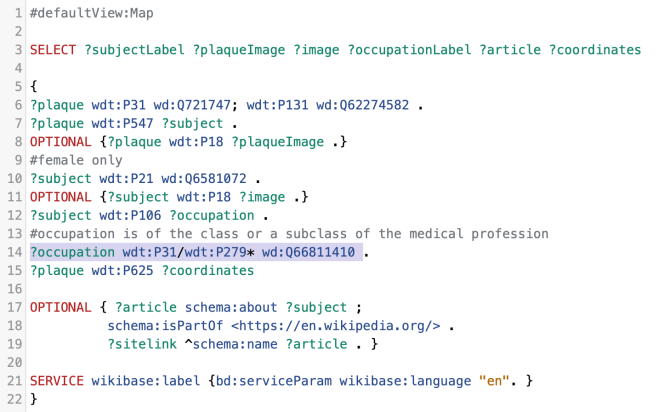
I really like Quickstatements, but there are a few areas in which it’s fiddly, including coordinates and dates. I’m really interested in looking further into Wikibase CLI for dates in particular, as the process there for dates (documented here) looks to be substantially easier in terms of data prep than it does in Quickstatements. Many thanks to Tony for that work, as his expertise saved us a lot of time! He also used that tool to create items for those women commemorated who were missing from Wikidata, documented here.
As with dates, coordinates are entered into Quickstatements in a different format than that which you’d use manually inside Wikidata itself, hence the formatting you’ll see in column Q on the Data collection tab. Most of this we had to grab from Google Maps, which again is a bit fiddly.
Quickstatements
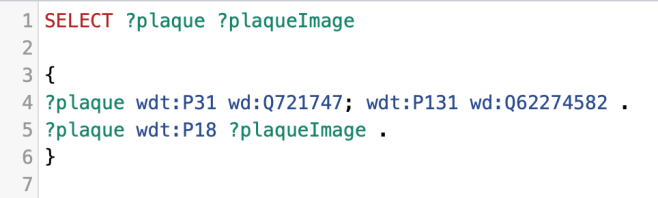
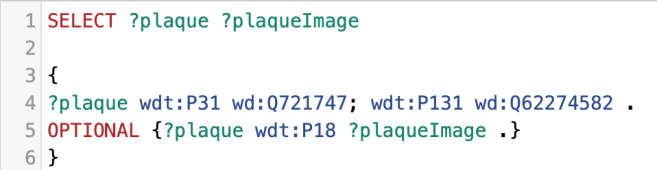
Once we had a master list of QIDs for the memorials we were working with, we could use Quickstatements to bulk upload sets of statements to those items.
For example, matching the memorials to the women commemorated, using this format:

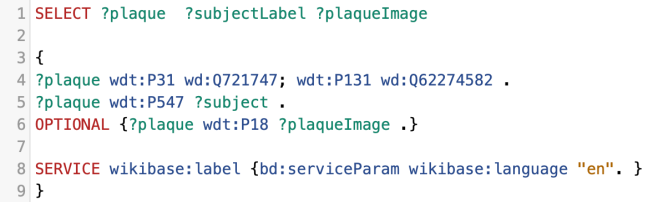
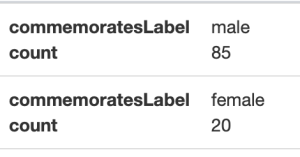
The Q numbers on the left are those of the memorials, P547 is “commemorates”, and the Q numbers on the right are those of the women celebrated. We were also able to add P8050 (Women of Scotland subject ID) to some women who already had entries on Wikidata, but no WoS ID.

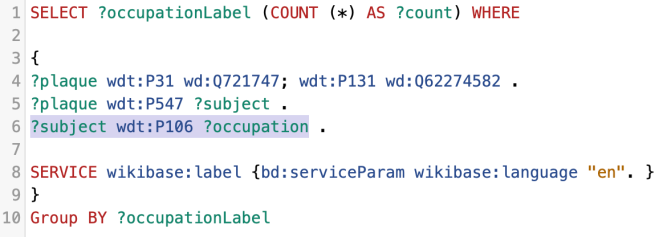
The Q number on the left again is the memorial, P31 is “instance of”, and the Q number on the right corresponds to a type of thing – a commemorative plaque, a garden, or a road, for example.
Once you’ve got the info in this format, it’s just a case of copy & pasting into QS, clicking import, and then run. (Note – you do need to be an autoconfirmed user to use QS, which means that your account must be at least 4 days old, and having more than 50 edits.) It’s relatively easy, and I was pleased that one of our relatively-new-to-Wikidata participants had the chance to make her first bulk uploads (description & commons category) using the tool over the weekend.
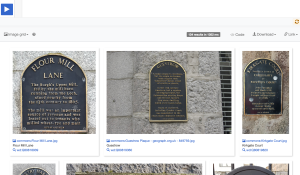
Photos
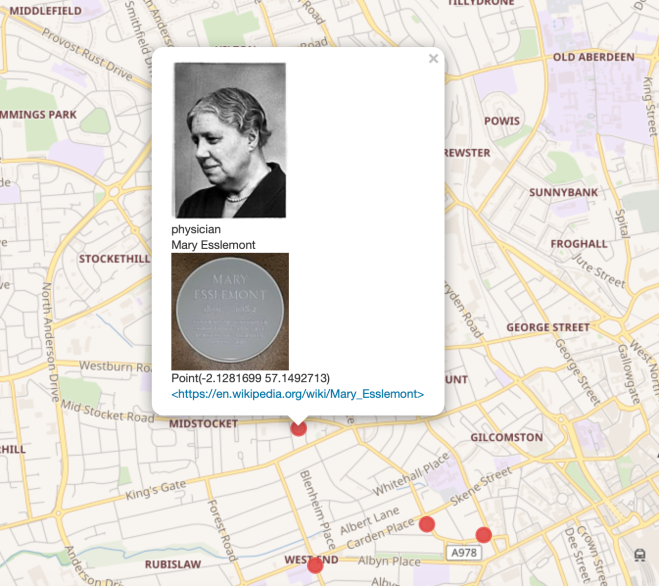
This project grew out of a desire to increase the coverage of Scottish heritage on Wikimedia Commons, so it was great to take some time on this. Mapping Memorials does have some images, but they’re not openly licensed, and others are missing. After Wikimedia Commons, our next port of call was Geograph, where many images have been released on Wiki-compatible Creative Commons licenses. Using Geograph2Commons, images can easily be transferred over to Wikimedia Commons, so that they can be used in any Wikimedia Project. Geograph also links to this feature from their site – click on “Find out how to reuse this image”, and then scroll down to “Wikipedia template for image page”, then click on the “geograph2commons” link. Really simple. Our group did some detective work for images, and then added them to Commons, and linked them manually to the Wikidata item.
This gave us a list of missing images… which is fine, but wouldn’t it be better to see them on a map?
Visualisation and filling the gaps
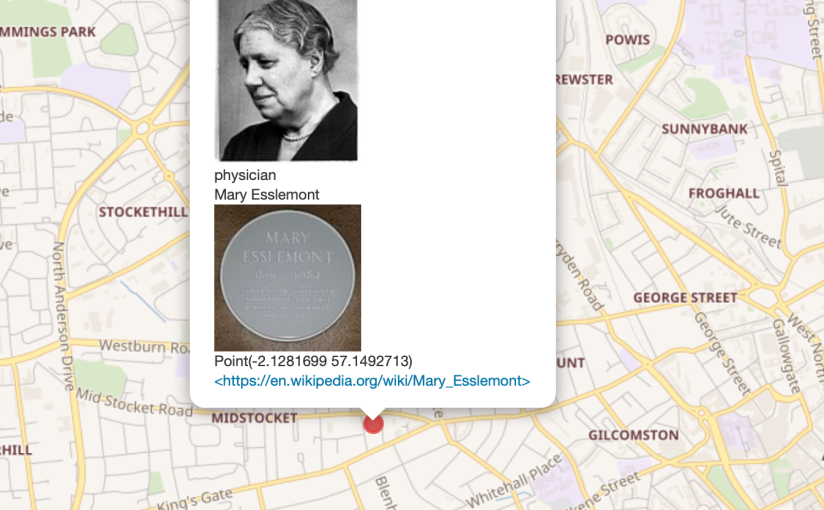
Thanks to Ian’s tutorial on how to create a custom WikiShootMe map, we were able to create a custom map that showed us which of the memorials we were working on had images, which didn’t, and where they were. That map is here, and it was great to see it slowly turn more green than red over the weekend as we found more images, or as volunteers headed out across Aberdeen between days to take missing pictures.

One of the small, but very satisfying, things you can do with these kinds of images is to integrate them into relevant Wikipedia articles. I added images from the project to the articles for Aberdeen Town House, Caroline Phillips, and Katherine Grainger. At the time of writing, around 2500 people have viewed those articles since I added the images.
Next steps
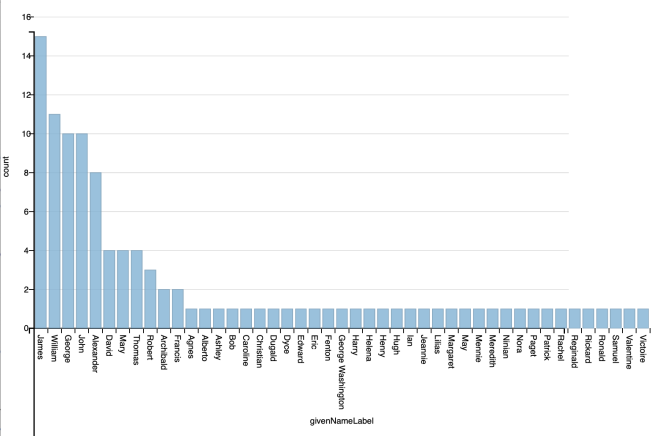
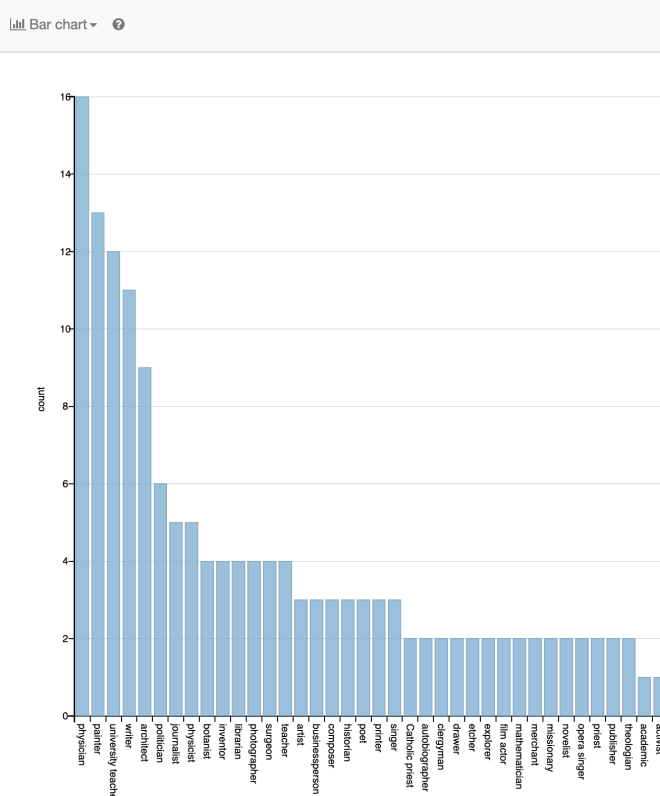
Over the course of the weekend we added 77 new memorials, and 26 new women to Wikidata, as well as a whole host of new photos. These entries all had some quite rich data, and as complete as we could make it.
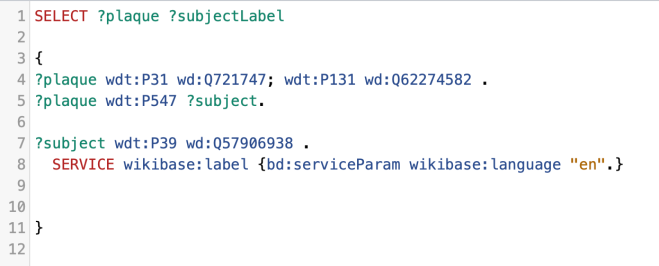
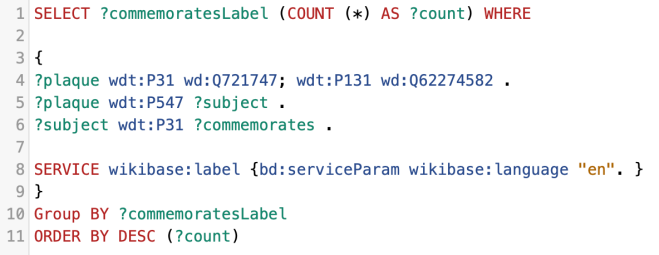
We were surprised to see some of the individuals who didn’t have a Wikipedia article – and of course, we can use the Wikidata query service to identify those gaps. The queries below could give us a great starting point for an editathon, or indeed, for any Wikipedia editor interested in writing Women’s biography.
- Wikidata query for women with a Women of Scotland subject ID, a memorial in Aberdeen, but no enwiki article: https://w.wiki/YVH
- Wikidata query for women with a Women of Scotland subject ID, but no enwiki article: https://w.wiki/YVG
Huge thanks to the team, and to Code the City for another great hack weekend!
Dr Sara Thomas
Scotland Programme Coordinator, Wikimedia UK
——————————————————————————
Header image: The Grave of Jessie Seymour Irvine by Ian Watt on Wiki Commons (CC-BY-SA)





















{kind=link}