
On Saturday 14th December 2019 we ran a one-day mini hack event. The idea behind it was for people to come along for a day to work on their side projects and, if they needed support, attempt to persuade others to assist them.
That’s what I did with my Aberdeen Plaques project: something I’d had on the back burner for more than a year.
Why do it?
The commemorative plaques which are dotted around the city are a perfect candidate for open data. They have a subject, usually some dates, are located somewhere, and are of different types etc. Making that all available as open data would open up a whole range of possibilities.

If we captured all of that well then we could do analysis on the data (ratio of women to men, most represented professions), create walking routes (maybe one for the arts, one for the sciences and so on), create timelines to see what periods are more represented.
Having recently trained as a WikiMedia UK trainer – and having experimented with some of the tools (Wiki Commons, Wiki Data, Wikipedia, Histropedia) I was convinced that these were the right way to go.
Pre-event prep
So, in advance of the hack day I’d done a bit of prep in the two weeks running up to the day iteself.
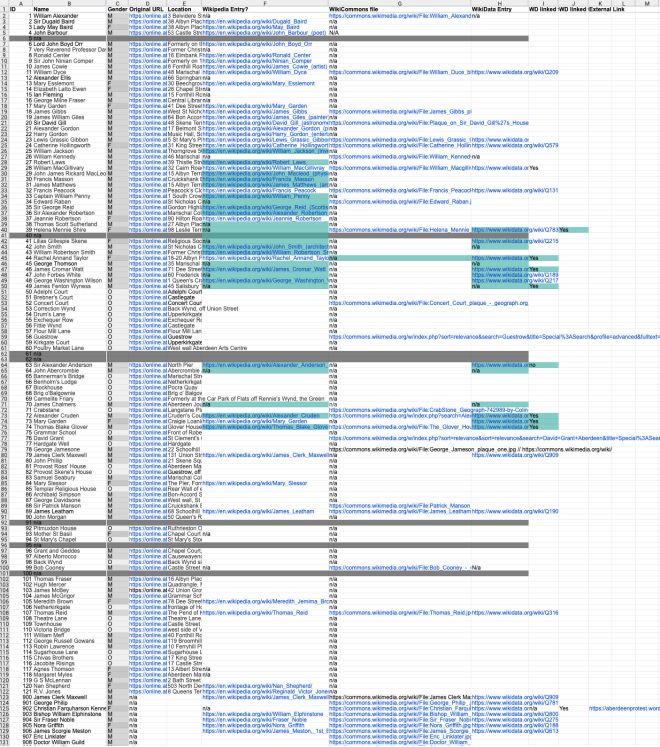
I’d created a spreadheet which recorded the
* subject (person or ‘thing’)
* Gender if known
* the link to the now-retired city council plaques system (hidden from public view)
* The location if known
* The geo coordinates (to be determined)
* Whether the subject had a Wikipedia page (tbd)
* Whether there was an image of the plaque on Wiki Commons (tbd)
* Whether the subject of the plaque was represented on Wiki Data (tbd)
* Any identifiers on Open Plaques (tbd)
* Any external links (eg to Flickr for photos)
I’d then populated some of the data (eg whether there were images of the plaque on Wiki Commons) as well as some other bits. But most cells were blank.
As a keen walker and photographer I had also photographed and uploaded seventeen plaque images to Wiki Commons in the lead up, so that we would have some images to work with.
How to use our time most effectively on the day?
Our aim for the day was then to find out what data / info / images existed, fill in the gaps, and explore how to use WikiData to store and retrieve data, and how we could potentially create maps, timelines and similiar new products.
What we did on the day
At the start of the event we pitched our project ideas, and I managed to persude five others (Angela, Mike, Stephen, James and Steve) to join me in working on the plaques project.
Angela and Mike, and later Angela and Stephen would go out and take photographs. Steve, James and I would work on the data capture, completing research on what existed, creating new entries for the data on Wiki Data, and testing queries on the Wiki Data query service.
How we did it
We used the spreadsheet that I had set up to capture all of the data we’d gathered – and as it eveolved it would show progress as well as what was still lacking. We had no expectations that we would do it all on the day, but we could pick away at it in future weeks and months.
In the run-up to the event I’d discovered The Pingus’ album of plaques photographs on Flickr. Sadly these had not been published with a licence that would allow us to use them. I’d sent a request, a few days before CTC18, for them to change the licence for the Aberdeen plaques pictures to a CC-SA one. This would have allowed our republishing on Wiki Commons. Sadly it didn’t elicit a response. But the album did show that there were many more plaques than the old ACC system listed. And it was possible to get co-ordinates from them. So the number of plaques to deal with kept growing.
During the day James filled in loads of gaps in which subjects were on Wikipedia and which on Wikidata.
Steve and I experimented with capturing and querying the data. Structuring that in a way that aids recall through Wiki Data Query Service was an interative process. Firstly I tried adding a statement ‘commomorative plaque image’ (P1801) into the wikidata record for the subject as you can see in this first example https://www.wikidata.org/wiki/Q2095630. But that limited what we could do.
So, we discovered that we could create a new object which was an instance of commemorative plaque. Our first attempt was https://www.wikidata.org/wiki/Q78438703 and we evolved what we captured there – adding statement, and Steve discovered the ‘openPlaques plaque ID'(P1893). Incidentally we also tried ‘openplaques Subject ID’ (P1430) but adding that to the plaque object throws an error. The latter should be added to the person record not the plaque.
At the end of CTC18
We ended the day with
- 138 plaques listed.
- 57 sets of co-ordinates identified
- 68 Wikipedia articles identified as matching plaque subjects (and eleven plaques subjects who had NO wikipedia page)
- 36 Images in WikiCommons
- 77 WikiData entries for the subject of the plaques (existing or created)
- 11 new wikidata entries for the plaques themselves
This was a great leap forward in one day and would pave the way for future work.
What next?
Since CTC18 ended, I’ve got firmly stuck into this project over the xmas break. Over the last three weeks I have now photographed over a hundred plaques (plenty of walking) and have created wikidata entries for most plaques and also their subjects in wikidata.
I’ll cover all of that, and how we can now use the data in part two, coming soon.

2 thoughts on “Aberdeen Plaques – Part One”