Code The City is a civic hacking initiative focused on using tech and (open) data for civic good. We use hack weekends, open data, workshops, and idea generation tools. We run Data Meetups, the Aberdeen Python User Group and the annual Scottish Open Data Unconference
This was one of three projects which were worked on during CTC24 – Open In Practice. We asked Jan Ainali, who led the project, to explain it for those who were not present at the weekend event.
Why did we run this project?
On Wikidata, there is a WikiProject for getting all the government agencies of all levels and the whole world properly modeled. Since it is a huge project, every way to try to break it down to bite size pieces are necessary. Work on the UK was already started, so it made a lot of sense trying to complete Scotland.
Work done before CTC24
In October during Scottish Open Data Unconference 2021 we got started on this task. We found some good sources and made fine progress, completing several categories of agencies. By completing here, I mean that we made sure there were items in Wikidata representing the agencies and that they were well enough modeled so that we could query for them. But we weren’t done, and some of the trickiest parts remained.
What we achieved at CTC24, what impact we hope it will have
With a joint effort, we managed to sort out how the judicial system was organized, which was something that remained unclear since the last session. Most time was spent in researching to understand it, and when that was done, it was fairly straightforward to create items for the courts that were missing and to model the others in a way that made it possible to query for them. We also managed to sort out some other small tasks from the last event, and finally we could produce one huge query to get all Scottish agencies at once: https://w.wiki/4TpN
Now we think this is the most complete and up-to-date list of Scottish agencies. If we are wrong about that, we would love feedback so that we can improve it.
What next – how can people get involved?
A few things are happening right now. First, we are importing agencies into the Govdirectory platform that is a more user-friendly view of Wikidata. We have already imported the local authorities, NHS boards and Health and Social Care Partnerships. You can find that data here: https://www.govdirectory.org/united-kingdom/
Since the large query was a bit messy, we will also try to improve the modeling in Wikidata. You are more than welcome to help with this. This will make queries for everybody simpler, and we will continuously be importing more agencies to the platform as we get done.
You can also help by adding contact points like email, official websites, social media accounts to the Wikidata items. You can either use the Wikidata button on the Govdirectory website, or you can go to the WikiProject page on Wikidata and run some queries there to find items to improve. https://www.wikidata.org/wiki/Wikidata:WikiProject_Govdirectory/United_Kingdom
Header Image by Jan Ainali, CC0, via Wikimedia Commons
It’s all going on in Scotland in March. As we spring into Spring (nearly there!), we’re very excited to be sponsoring, and going, to theScottish Open Data Unconference in Aberdeen on 14th and 15th March. Topics are pitched in the morning of each day, an agenda is created and participants talk as much as the chair.
Our colleagueJamie Whyte is lucky enough to have a ticket, so if you spot him do say hi! Here are some recent open data happenings we’ve picked up on our radar…
Scottish Index of Multiple Deprivation
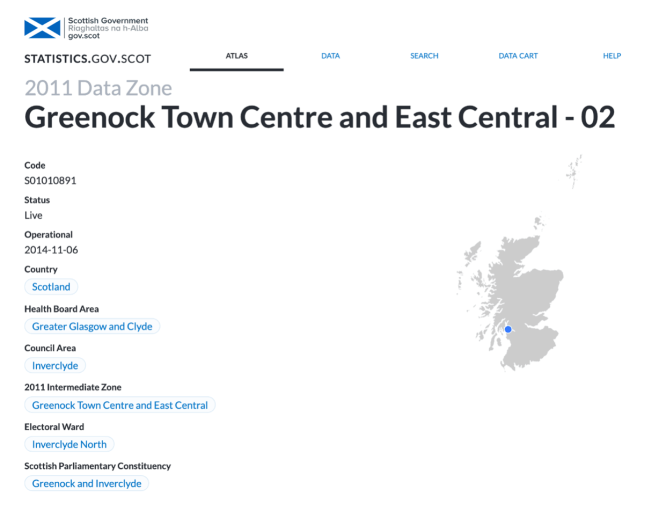
The Scottish Index of Multiple Deprivation was released late January and we loved the accompanying briefing document, which put the numbers into context (find ithere). The data’s also available on theScottish Government’s Open Data site, where you can use the Atlas section to find key data zones and see key facts about them. The below screenshot is of thedata zone which is ranked as the most deprived in the 2020 SIMD.
Summary matrix of Scottish Index of Multiple Deprivation 2020, by council area – shows % of each council's data zones by deprivation decile – highest decile highlighted in each row (e.g. 37% of East Renfrewshire in least deprived, 32% of Inverclyde's in most deprived 10%) pic.twitter.com/SwcgBipo51
Another thing we’ve noticed is that there’s preliminary work happening on GraphQL and RDF, which aims to serve as a case for future standardisation. More on thishere, where you can send a request to join the group if this is your bag. It’s definitely ours!
A new W3C Community Group has been launched to bridge the worlds on #GraphQL and #RDF. Main goals are analysis of existing approaches, use case and requirement collection, to serve as a basis for future standardization efforts.https://t.co/peTAu0JNO7
Last, but not least, collaboration. This is a wide concept but it’s also a trend that’s cropping up in different aspects of working with open data. Here are some we’ve noticed:
Scotland is one of 90 members of the countries taking part in theOpen Government Partnership (OGP), and just one of 15 chosen to contribute to its leadership and innovation. Thesecond OGP Action Plan is now in its final year and aims to:
“promote trust and co-operation between government and civil society.”
The Office for National Statistics is publishing data in a collaborative project across a spread of organisations including ONS, HMRC, MHCLG, DWP and DIT. The Connected Open Government Statistics (COGS) project involves a lot of technical collaborative work in harmonising codelists, as well as harmonising a data model and all the processes that go into it. More on this projecthere on the GSS blog site.
2019 saw a growing, collaborative API community, with API events involving government and people working with government. We went to one in Newcastle andanother one’s arranged for March 16th (if you’re still hungry for more after the unconference!)
The Open Data Institute have been busy, busy, busy.Jeni Tennison spoke about the idea of how collaboration is key for new institutions of the data age, at our Power of Data conference in October (catch that video here). The ODI have also been working on a data and public services toolkit & there’s anintroductory eventto this in Edinburgh just a few days before the Scottish Open Data Unconference.
The evening before Code The City 18 I started to think about what fun project to spend the day doing at our one day mini-hack event. After reading Ian Watt’s blogpost about Wikidata and spending 10 minutes or so playing around with it, I decided a topic for further experimentation was required.
At the time of writing, I’m just over a third of the way through my very interesting part-time online MA Railway Studies at University of York. Looking at Britain’s railways from their very beginning, there are many railway companies from 1821 onwards. Some of these companies merged, some were taken over, others just disappeared whilst others were replaced by new companies. All these amalgamations eventually led to the “Big Four” groupings in 1923 and then on to British Railways in 1948’s railway nationalisation. British Railways rebranded as British Rail in 1965 and then splintered into numerous companies as a result of the denationalisation of the 1990s.
With the railway companies appearing in some form or another in Wikipedia, I thought it would be useful to be able to pick any railway company and view the chain of companies that led to it and those that followed. The ultimate goal would be to be able to bring up the data for British Rail and then see the whole past unfold to the left and the future unravel to the right. In theory at least, Wikidata should allow me to do that.
No software coding skills are required to see the results of my experimentation: by clicking on the links provided (usually directly after the code) it is possible to run the queries and see what happens. However, using the code provided as a start, it is possible to build on the examples to find out things for yourself.
Understanding Wikidata and SPARQL
SPARQL is the query language used to retrieve various data sets from Wikidata via the Wikidata Query Service.
As is always the case with anything software related, the examples and tutorials never seem to handle those edge cases that you seem to hit within the first 5 minutes. Maybe I hit these cases so soon due to jumping straight from the “hello world” of requesting all the railway companies formed in the UK to trying to build the more complex web of railway companies rather than working my way through all the simpler steps? However, my belief is to fail quickly, leaving plenty of time left to fail some more before succeeding, after all you never see a young child plan out a strategy when they are learning to get the different shaped blocks through the correct holes.
At the time of writing…
Comments about the state of certain items of data were relevant at the time I wrote this article. As one of the big features of Wikidata is it constantly being updated, expanded and corrected, the data referenced may have changed by the time you read this. Some of the changes are those I’ve made in reaction to my discoveries, but I have left some out there for others to fix.
A simple list
First off, I created a simple SPARQL query to request all the railway companies that were formed in the UK.
SELECT ?company ?companyLabel WHERE { ?company wdt:P31 wd:Q249556; wdt:P17 wd:Q145 . SERVICE wikibase:label { bd:serviceParam wikibase:language “en”. } } ORDER BY (lcase(?companyLabel))
The output of this query can be seen by running it yourself here by clicking on the white-on-blue arrow displayed on the Wikidata Query Service console. It is safe to modify the query in the console without messing up my query as any changes cause a new bookmarked query to be created. So please experiment as that’s the only way to learn.
Now what does the query mean and where do all those magic numbers come from?
wdt:P31 means get me all Wikidata triples (wdt) that have the property instance of (P31) that is has a value of railway company (Q249556).
wdt:P17 means get me all of the results so far that have the property country (P17) set to United Kingdom (Q145).
Where did I get those numbers from? First, I went to Wikipedia and searched for a railway company, LMS Railway, and got to the page for London, Midland and Scottish Railway. From here I went to the Wikidata item for the page.
Wikipedia page for LMSR that shows how to get to the Wikidata
From here I hovered my pointer over instance of, railway company, country and United Kingdom to find out those magic numbers.
Wikidata page for LMSR
Some unexpected results
Some unexpected companies turned up in the results list due to my query not being specific enough. For example, Algeciras Gibraltar Railway Company, located in Gibraltar but with headquarters registered in the UK the data has its country as United Kingdom. To filter my results down to just those that are located in the UK I tried searching for those that had the located in the administrative territorial entity (P131) with any of the following values:
However, that dropped my result set from 228 to 25 due to not all the companies having that property set.
Note: When trying to find out what values to use it is often quick and easy to run a simple query to ask Wikidata itself. To find out what all the values were for UK countries I wrote the following that asked for all countries that had an instance of value of country within the United Kingdom (Q3336843):
select ?country ?countryLabel WHERE { ?country wdt:P31 wd:Q3336843 . SERVICE wikibase:label { bd:serviceParam wikibase:language "en". } }
In order to see what other information could easily be displayed for the companies, I looked at the list of properties on the London, Midland and Scottish Railway. I saw several dates listed so decided that would be my next area of investigation. There is an inception (P571) date that shows when something came into being, so I tried a query with that:
SELECT ?company ?companyLabel ?inception WHERE { ?company wdt:P31 wd:Q249556; wdt:P17 wd:Q145 . ?company wdt:P571 ?inception SERVICE wikibase:label { bd:serviceParam wikibase:language "en". } } ORDER BY (lcase(?companyLabel))
This demonstrated two big issues with data. Firstly, the result set had dropped from 228 to 106 indicating that not all the company entries have the inception property set. The second was that only one, Scottish North Eastern Railway, had a full date (29th July 1856) specified, the rest only had a year and that was being displayed as 1st January for the year. Adding the OPTIONAL clause to the inception request returns the full data set with blanks where there is no inception date specified.
SELECT ?company ?companyLabel ?inception WHERE { ?company wdt:P31 wd:Q249556; wdt:P17 wd:Q145 . OPTIONAL { ?company wdt:P571 ?inception. } SERVICE wikibase:label { bd:serviceParam wikibase:language "en". } } ORDER BY (lcase(?companyLabel))
Railway companies are not a straightforward case when it comes to a start date due to there being no one single start date. Each railway company required an Act of Parliament to officially enable it to be formed and grant permission to build the railway line(s). This raises the question: is it the date that Act was passed, the date the company was actually formed or the date that the company commenced operating their service that should be used for the start date? Here is a revised query that gets both the start time (P580) and end time(P582) of the company if they have been set:
Unfortunately, of the 228 results only one, London, Midland and Scottish Railway, has a startTime and endTime, and London and North Eastern Railway is the only with endTime. Based on these results it looks like that startTime and endTime are not generally used for railway companies. Looking through the data for Scottish North Eastern Railway did turn up a new source of end dates in the form of the dissolved, abolished or demolished (P576) property. Adding a search for this resulted in 9 companies with dissolved dates.
There is no logic in which companies have this property: they range from Scottish North Eastern Railway dissolving on 10th August 1866 to several that ended due to the formation of British Railways, the more recent British Rail ending on 1st January 2001, and the short lived National Express East Coast (1st January 2007 – 1st January 2009). However, once again, the dates are at times misleading as, in the case of National Express East Coast, it is only the year rather than full date in the inception and dissolved, abolished or demolishedproperties.
Some of the railway companies, such as Underground Electric Railways Company of London, have another source of dates and that is as part of the railway company value for their instance of. It is possible to extract the start and end dates if they are present by making use of nested conditional queries. In the line:
Another date that can be used to work out the start and end of the companies can be found hanging off the values of very useful pair of properties: replaced by (P1366) and replaces (P1365). This conveniently connects into the next part of my exploration that will follow in Part Two. Although, as with many railway related things, the exact time of arrival of part two cannot be confirmed.
On Saturday 14th December 2019 we ran a one-day mini hack event. The idea behind it was for people to come along for a day to work on their side projects and, if they needed support, attempt to persuade others to assist them.
That’s what I did with my Aberdeen Plaques project: something I’d had on the back burner for more than a year.
Why do it?
The commemorative plaques which are dotted around the city are a perfect candidate for open data. They have a subject, usually some dates, are located somewhere, and are of different types etc. Making that all available as open data would open up a whole range of possibilities.
Some Aberdeen plaques
If we captured all of that well then we could do analysis on the data (ratio of women to men, most represented professions), create walking routes (maybe one for the arts, one for the sciences and so on), create timelines to see what periods are more represented.
Having recently trained as a WikiMedia UK trainer – and having experimented with some of the tools (Wiki Commons, Wiki Data, Wikipedia, Histropedia) I was convinced that these were the right way to go.
Pre-event prep
So, in advance of the hack day I’d done a bit of prep in the two weeks running up to the day iteself.
I’d created a spreadheet which recorded the
* subject (person or ‘thing’)
* Gender if known
* the link to the now-retired city council plaques system (hidden from public view)
* The location if known
* The geo coordinates (to be determined)
* Whether the subject had a Wikipedia page (tbd)
* Whether there was an image of the plaque on Wiki Commons (tbd)
* Whether the subject of the plaque was represented on Wiki Data (tbd)
* Any identifiers on Open Plaques (tbd)
* Any external links (eg to Flickr for photos)
I’d then populated some of the data (eg whether there were images of the plaque on Wiki Commons) as well as some other bits. But most cells were blank.
Pre-event spreadsheet
As a keen walker and photographer I had also photographed and uploaded seventeen plaque images to Wiki Commons in the lead up, so that we would have some images to work with.
How to use our time most effectively on the day?
Our aim for the day was then to find out what data / info / images existed, fill in the gaps, and explore how to use WikiData to store and retrieve data, and how we could potentially create maps, timelines and similiar new products.
What we did on the day
At the start of the event we pitched our project ideas, and I managed to persude five others (Angela, Mike, Stephen, James and Steve) to join me in working on the plaques project.
Angela and Mike, and later Angela and Stephen would go out and take photographs. Steve, James and I would work on the data capture, completing research on what existed, creating new entries for the data on Wiki Data, and testing queries on the Wiki Data query service.
How we did it
We used the spreadsheet that I had set up to capture all of the data we’d gathered – and as it eveolved it would show progress as well as what was still lacking. We had no expectations that we would do it all on the day, but we could pick away at it in future weeks and months.
In the run-up to the event I’d discovered The Pingus’ album of plaques photographs on Flickr. Sadly these had not been published with a licence that would allow us to use them. I’d sent a request, a few days before CTC18, for them to change the licence for the Aberdeen plaques pictures to a CC-SA one. This would have allowed our republishing on Wiki Commons. Sadly it didn’t elicit a response. But the album did show that there were many more plaques than the old ACC system listed. And it was possible to get co-ordinates from them. So the number of plaques to deal with kept growing.
During the day James filled in loads of gaps in which subjects were on Wikipedia and which on Wikidata.
Steve and I experimented with capturing and querying the data. Structuring that in a way that aids recall through Wiki Data Query Service was an interative process. Firstly I tried adding a statement ‘commomorative plaque image’ (P1801) into the wikidata record for the subject as you can see in this first example https://www.wikidata.org/wiki/Q2095630. But that limited what we could do.
So, we discovered that we could create a new object which was an instance of commemorative plaque. Our first attempt was https://www.wikidata.org/wiki/Q78438703 and we evolved what we captured there – adding statement, and Steve discovered the ‘openPlaques plaque ID'(P1893). Incidentally we also tried ‘openplaques Subject ID’ (P1430) but adding that to the plaque object throws an error. The latter should be added to the person record not the plaque.
At the end of CTC18
We ended the day with
138 plaques listed.
57 sets of co-ordinates identified
68 Wikipedia articles identified as matching plaque subjects (and eleven plaques subjects who had NO wikipedia page)
36 Images in WikiCommons
77 WikiData entries for the subject of the plaques (existing or created)
11 new wikidata entries for the plaques themselves
This was a great leap forward in one day and would pave the way for future work.
What next?
Since CTC18 ended, I’ve got firmly stuck into this project over the xmas break. Over the last three weeks I have now photographed over a hundred plaques (plenty of walking) and have created wikidata entries for most plaques and also their subjects in wikidata.
I’ll cover all of that, and how we can now use the data in part two, coming soon.
Earlier this year Code The City held an Editathon with Wikimedia UK. The subject was the history of Aberdeen Cinemas. We ended up with 16 people all working together to create new articles, update existing ones, capture new images for Wiki Commons, and generate or enhance WikiData items. This was a follow up to previous sessions that Dr Sara Thomas of WikiMedia UK led for us in the city, mainly for information professionals.
This has led to significant interest from cultural bodies in the city in using the suite of WikiMedia platforms and tools to improve access to their collections in Aberdeen. We expect to do quite a bit more of this with them in 2020.
Two weeks ago I attended a Train the Trainer 3-day workshop in Glasgow for Wikimedia UK to become a trainer for them in Scotland. That will see me training professionals and volunteers in how to use Wikipedia, Wiki Commons and Wikidata in particular.
In this blog post I explain why you might want to use some of the fancy features of WikiData query service, show you how to do that, using on my adaptation of others’ shared examples, and encourage you to experiment for yourself.
Wikidata
Wikidata uses a Linked Open Data format to store data. While I have added quite a number of items to Wikidata I’ve not had a chance to really study how to use SPARQL (the query language behind the scenes) to to execute queries against the data. This is done in the Wikidata Query service. This is a key skill to using some of the more advanced features. Without the means to extract data there is little point in stuffing data into it. In fact WikiData allows us to do some very fancy things with the data which we retrieve.
So, I decided this week to start working on that. This describes the first steps I have been doing. It should also provide a simple introduction to any else wanting to dip their toe in the SPARQL waters.
Where to start?
This 16-minute tutorial on Youtube is a great place to begin; it is where I started. It describes how to create a simple query and build it up to something more powerful. I copied what it did then adapted that to build a query that I wanted. I suggest that you watch it first to understand what each line of SPARQL is doing.
Here are the steps, mainly frown from and adapted from that tutorial.
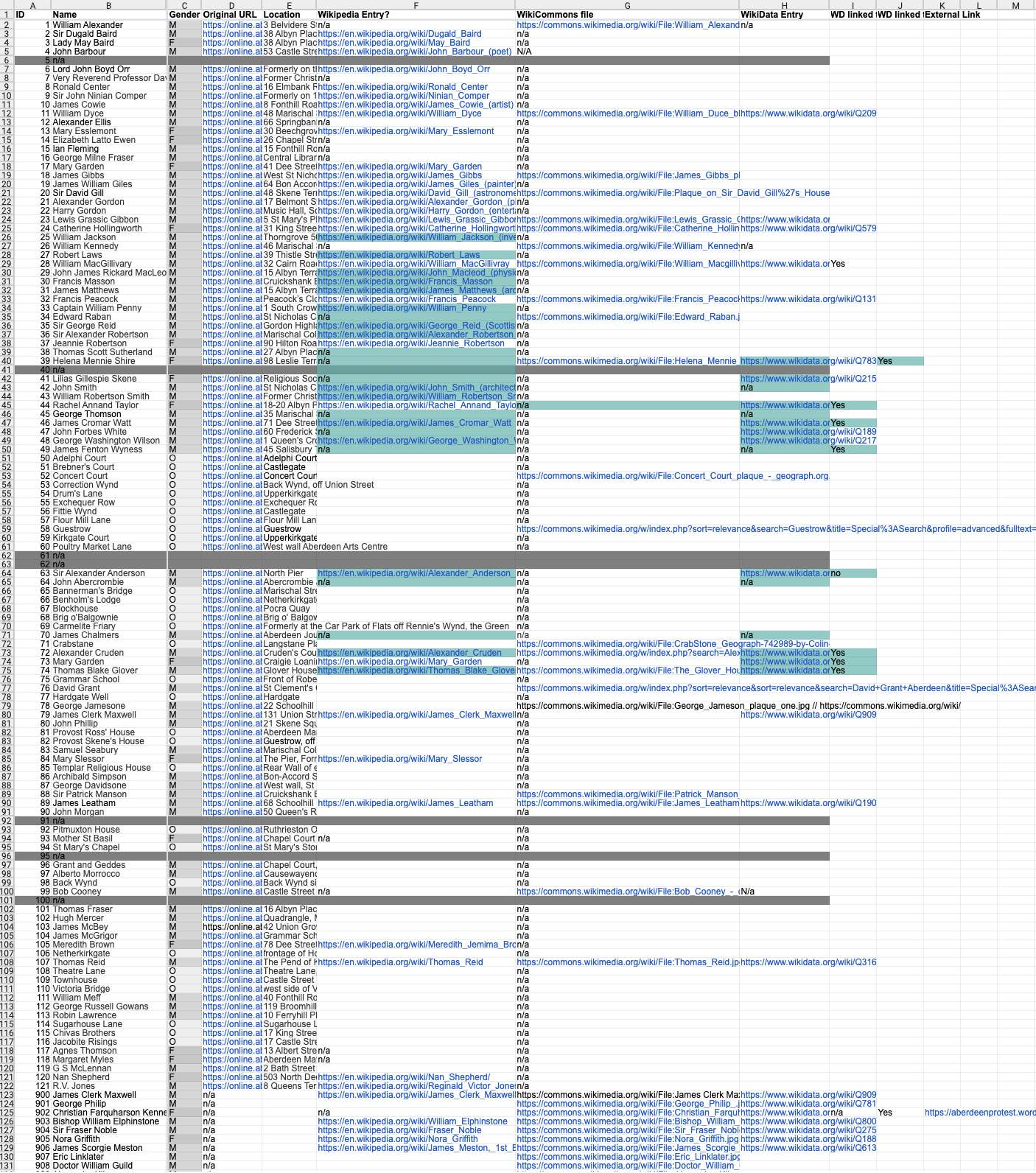
Find all female graduates of Aberdeen University
In the query above we use the Educated at statement (P69) and the identifier for Aberdeen University (Q270532 ) in combination with the Sex or gender statement (P21) with the Female identifier (Q6581072).
You can run this for yourself here using the white-on-blue arrow. I’ve used one of the great things you can do with Wikidata which is to share this query using the link symbol on the left of the page just above the arrow:
Save a Wikidata query
Changing the parameters of the query means that we can check males (Q6581097) against females (Q6581072). Or you can compare different universities. To do this go to the Wikidata homepage and search for the name of the institution. The query will return a page with the Q code in the title. Thus we can compare various universities by amending the Q code in the query above: University ofAberdeen (Q270532) with University of Glasgow (Q192775) or Edinburgh University (Q160302).
Running these queries we can see that the number of both male and female graduates with entries on WikiData of Aberdeen University is significantly smaller than from either Glasgow or Edinburgh, and we can see that the proportion of females of all graduates for each university is smallest for Aberdeen.
University
Male Grads
Female Grads
% Female
Aberdeen
944
125
11.7
Edinburgh
3804
571
13.1
Glasgow
1562
291
15.7
The results of these queries should themselves cause us to reflect on the relatively smaller number of results of either gender from Aberdeen compared to the other universities; and also the smaller proportion of women. It suggests that there is some work to do to ensure that we get better representation of both genders in Wikidata.
Enhancing our query
Now that we have a basic query we can retrieve additional bits of data for the subjects of the query including place of birth, date of birth and images.
These are represented by P19 (birth place), P560 (date of birth) and P18 (image). As we see in the example below, when we query these we follow them with a name we assign to the item returned (e.g. ?person wdt:P19 ?birthPlace ) and we add the name we give it, in this case ?birthPlace to the Select statement on the first line of the query, ensuring that it will feature in the data returned in the table or other format output.
enhanced wikidata query
You will note that the above example now uses the ?birthPlace to create a new query to get the co-ordinates (P625) of that place which we assign to coordinates:
> ?birthPlace wdt:P625 ?coordinates
and we include coordinates in the first line of things we will display.
Advantages of extra data elements
By having birthplace coordinates we can plot the results in a map which is easily done using the tools built into the wikidata query service.
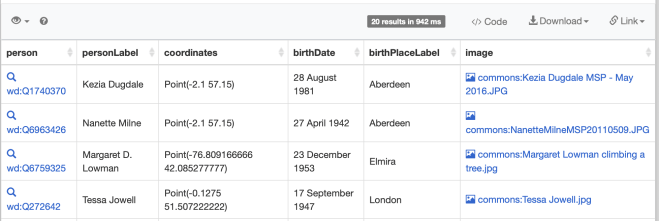
Run the query (white arrow on blue on the left menu) and observe the table that was returned. You can see that the first line of the Select statement formed the columns of the table.
Table of wikidata query results
Note that instead of 125 results as we had in the simple query, we only get 20 results. My understanding of this is that we are specifying records which must have a place of birth, an image etc. Where these do not exist then they records for that person are not returned. This in itself shows that there is a piece of work to do to identify where records in the batch of 125 lack these elements and fix them.
In fact you could say that there is a whole cycle of adding data, querying it, spotting anomalies, fixing those and re-querying which leads to substantial enrichment of the data.
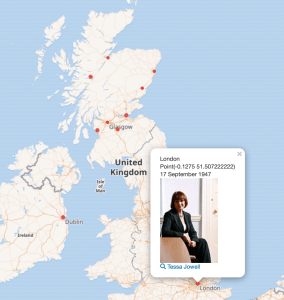
Map results
Now click on the dropdown by the eye symbol, on the left immediately above the results, and choose the map option. The tool will generate a map with a pin in the location of each place of birth. You can pan and zoom to the UK and click on each pin. Try it. To get back to the query, click on the arrow, top-right.
Wikidata map view with clicked point
A timeline
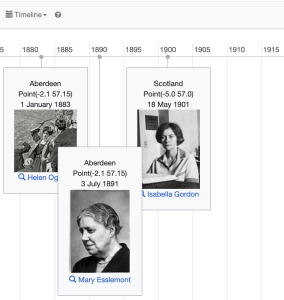
Now click on the eye symbol to show other options, and choose Timeline.
As we can see below, the Wikidata query service will construct a rudimentary timeline with relatively little effort. This is one of its great features. So far we have the same 20 complete records – and the cards or tiles are titled by the place of birth but we can change that.
Wikidata timeline
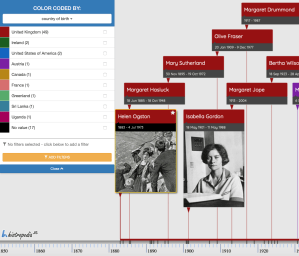
Enhancing the timeline on Histropedia
To improve on our timeline we can construct a better query using the Wikidata Query Service then paste it into the Histropedia service to run it. Our first version which makes small improvements on our previous timeline produces the results below. This labels by the person’s name, and colour codes the individual records by place of birth label. To see the code, click the gear wheel at the top right of the screen. Note we still only retrieve 20 results.
A first query on Histropedia
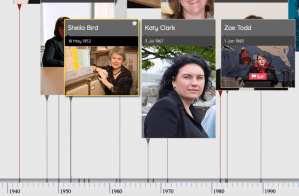
We can substantially enhance this query as we have done on the following version. This makes certain items optional, gets the country of birth and colour-codes by that, and ranks the records by prominence (with the most prominent at the front). If I understand it correctly by using optional elements it also retrieves 76 records, much more than previously.
enhanced Histropedia timeline
I would encourage you to watch the tutorial video at the start of this post, then try to hack some of the queries to which I provided links. For example how many female graduates of the Robert Gordon University would each query generate? How would you find the Q code of that institution? Have fun with it!










{kind=link}