
This is project started as part of CTC21: Put Your City on the Map which ran Saturday 28th Nov 2020 and Sunday 29th Nov 2020. You can find our code on Github.
There are thousands of ship wrecks off the coast of Scotland which can be seen on Marine Scotland’s website

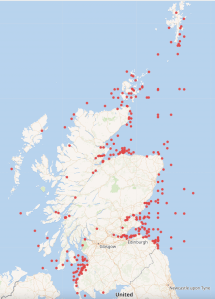
In Wikidata the position was quite different with only a few wrecks being logged. The information for the image below was derived from running the following query in Wikidata https://w.wiki/nDt

Day one – sourcing the information of the wrecks.
The project started by research various website to obtain the raw data required. Maps with shipwrecks plotted were found but finding the underlying data source was not so easy.
Data on Marine Scotland, Aberdeenshire Council’s website and on the Canmore website were considered.
Once data was found, the next stage was finding out the licensing rights and whether or not the data could be downloaded and legitimately reused. The data found on Canmore’s website indicated that it was provided under an Open Government Licence hence could be uploaded to Wikidata. This is the data source which was then used on day two of the project.
A training session on how to use Wikidata was also required on day one to allow the team to understand how to upload the data to Wikidata and how the identifiers etc worked.
Day two – cleaning and uploaded the data to Wikidata.
Deciding on the identifiers to use in Wikidata was the starting point, then the data had to be cleaned and manipulated. This involved translating Easting and Northings coordinates to latitude and longitude, matching the ship types between the Canmore file and Wikidata, extracting the reference to the ship from Canmore’s URL and general overall common sense review of the data. To aid with this work a Python script was created. It produced a tab separated file with the necessary statements to upload to Wikidata via Quickstatements.
The team members were new to Wikidata and were unable to create batch uploads as they didn’t have 4 days since creating their accounts and 50 manual edits to their credit – a safeguard to stop new accounts creating scripts to do damage.
We asked Ian from Code The City to assist, as he has a long editing history. He continues this blog post.
Next steps
I downloaded the output.txt file and checked if it could be uploaded straight to Quickstatements. It looked like there were minor problems with the text encoding of strings. So I imported the file into Google Docs. There, I ensured that the Label, Description and Canmore links were surrounded in double quotation marks. A quick find and replace did this.
I tested an upload of five or six entries and these all ran smoothly. I then did several hundred. That turned up some errors. I spotted loads of ships with the label “unknown” and every wreck had the same description. I returned to the Python script and tweaked it to concatenate the word “Unknown” with a Canmore ID. This fixed the problem. I also had to create a checking method of seeing if our ship had already been uploaded. I did this by downloading all the matching Canmore IDs for successfully uploaded ships. I then filtered these out before re-creating the output.txt file.
I then generated the bulk of the 24,185 to be uploaded. I noticed a fairly high error rate. This was due to a similar issue to the Unknown-named ships. The output.txt script was trying to upload multiple ships with the same names (e.g. over 50 ships with the name Hope). I solved this in the same manner as with Unknown-named wrecks, concatenating ship names with “Canmore nnnnnn.”
I prepared this even as the bulk upload was running. Filtering out the recently uploaded ships and re-running the creation of the Output.txt file meant that within a few minutes I was able to have the corrective upload ready. Running this a final time resulted in all shipwrecks being added to WIkidata, albeit with some issues to fix. This had taken about a day to run, refine and rerun.
The following day I set out to refine the quality of the data. The names of shipwrecks had been left in sentence case: an initial capital and everything else in lower case. I downloaded a CSV of records we’d created, and changed the Labels to Proper Case. I also took the opportunity to amend the descriptions to reflect the provenance of the records from Canmore in the description of each. I set one browser the task of changing Labels, and another the change to descriptions. This was 24,185 changes each – and took many hours to run. I noticed several hundred failed updates – which appear to just be “The save has failed” messages. I checked those and reran them. Having no means of exporting errors from Quickstatements (that I know of) makes fixing errors more difficult than it should be.
Finally I noticed by chance that a good number of records (estimated at 400) are not shipwrecks at all but wrecks of aircraft. Most, if not all, are prefixed “A/C’ in the label.
I created a batch to remove statements for ships and shipwrecks and to add statements saying that these are instances of crash sites. I also scripted the change to descriptions identifying these as aircraft wrecks rather than ship wrecks.
This query https://w.wiki/pjA now identifies and maps all aircraft wrecks.
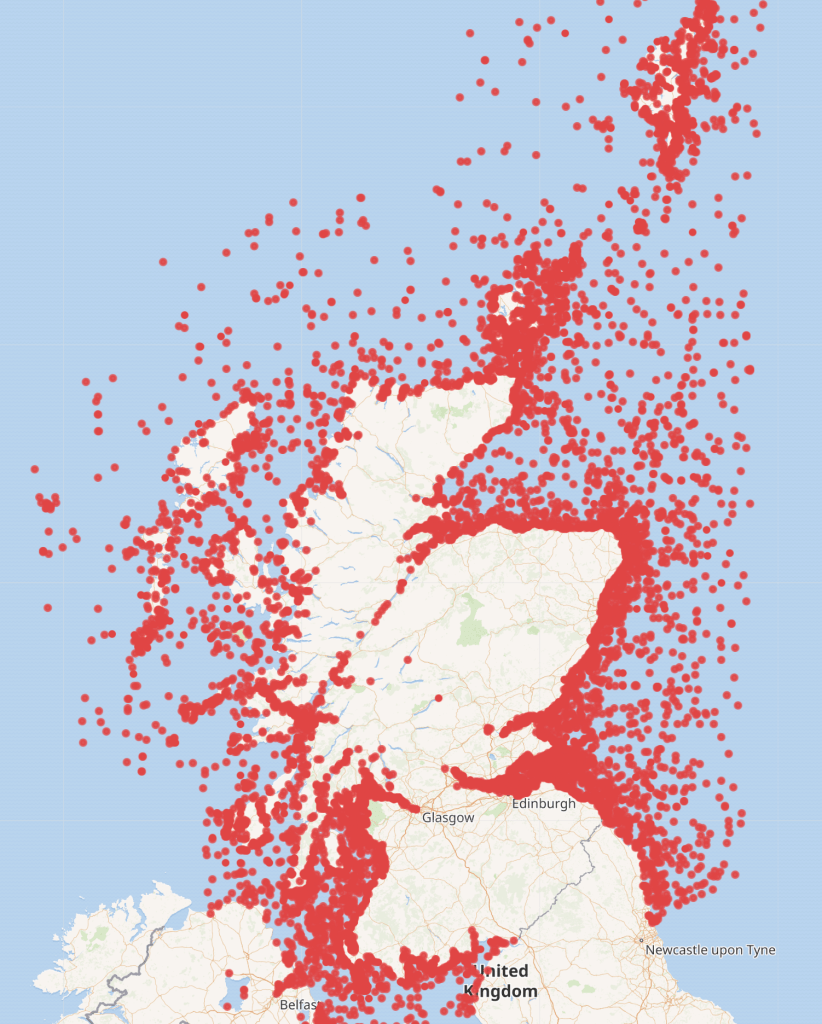
This query https://w.wiki/pSy maps all shipwrecks
Next steps?
I’ve noted the following things that the team could do to enhanced and refine the data further:
- Check what other data is available by download or scraping from Canmore (such as date of sinking, depth, dimensions) and add that to the wikidata records
- Attempt to reconcile data uploaded from Aberdeen built ships at CTC19 with these wrecks – there may be quite a few to be merged
Finally, in the process of working on the cleaning of this uploaded data I noticed the the data model on Wikidata to support this is not well structured.
This was what I sketched out as I attempted to understand it.

Before I changed the aircraft wrecks to “crash site” I merged the two items which works with the queries above. But this needs more work.
- Should the remains of a crashed aircraft be something other than a crash site? The latter could be cleared of debris and still be the crash site. The term Shipwreck more clearly describes where a wreck is whether buried, on land, or beneath the sea.
- Why is a shipwreck a facet of a ship, but a crash site is a subclass of aircraft.
- And Disaster Remains seems like the wrong term for what might be a non-disastrous event (say if a ship from the middle ages gently settled into mud over the centuries and was forgotten about – and certainly isn’t a subclass of Conservation Status, anyway.
I’d be happy to work with anyone else on better working out an ontology for this.

One thought on “Nautical Wrecks”