
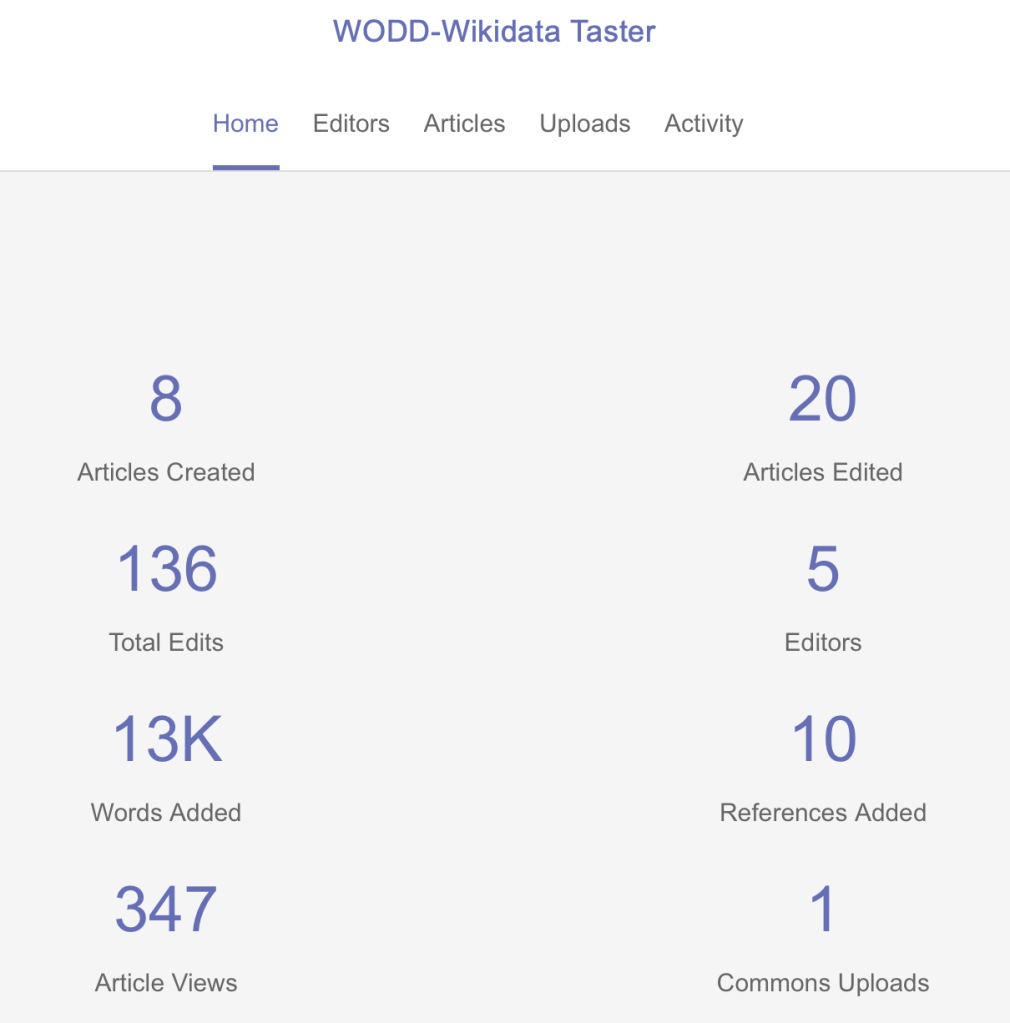
A guest blog-post by Sara Mazzoli, a post-graduate student at Edinburgh University, who has been interning at Code The City for the last three months. During this project she has worked closely with us and with the Aberdeen City and Aberdeenshire Archives.
Introduction: what is the Register of Returned Convicts?
Historical context, use and description
The Register of Returned Convicts of Aberdeen (1869-1939) is a fascinating, “small-but-chunky” (Astley, 2021) volume contained in the Aberdeen and Aberdeenshire Archives, comprising a total of 279 entries. It is located in the Grampian police collection of the Archives. Out of these entries, about sixty feature mug shots – which can be seen here.
As suggested by the register’s title, the register was used to take note of convicts’ addresses upon release. In fact, Phil Astley – Aberdeen’s Archivist – explained to us that this register contains information on convicts that were sentenced to Penal Servitude (often noted in the register as P.S.).
The Penal Servitude Act, enforced in 1857, was meant to substitute transportation with a prison sentence. This specific sentence consisted of three parts: solitary confinement; labour and release on licence. This latter element meant that individuals sentenced to P.S. had to report monthly to the police during their licence time. Also, they had to report any change in address within 48 hours.
A typical page of the Register looks like this:

As it can be seen, at the top of each page of the register, information was noted on convicts’ physical traits and age upon release, as well as conviction and sentence. In the “Marks” section, anything noteworthy – such as tattoos, scars, deformities and moles – was written down. In fact, according to Phil Astley the industrialisation process determined a high incidence of accidents in factories. Therefore, disfigurements were common amongst workers.
At the bottom half of the page, the register featured information on the convicts’ addresses after their sentence ended. Most of the addresses of the people noted in the register were in Aberdeen. However, some also moved to nearby towns and villages – such as Dundee – or to bigger cities, such as Edinburgh and Glasgow.
Moreover, Phil suggested that there are other two particular acts that shaped the register.
- The Habitual Offenders Act 1869.
- The Prevention of Crimes Act of 1871. This act
Simply put, these two acts tightened former criminals’ liberties, and enhanced police monitoring of these individuals. These laws were in fact especially crafted to fight habitual criminals (Radzinowicz and Hood, 1980): with increasing urbanization, authorities were concerned with what they labelled as “criminal classes”, an expression by which they referred to individuals who mainly lived through criminal activities. The Register can ultimately be understood as an example of the attempt to monitor the movements of these repeat offenders.
The mugshots and the “habitual criminal”
The camera was developed in the first half of the Nineteenth century, and was initially seen as a tool to represent bodies in a realistic manner. Indeed, photography was depicted as an objective and neutral representation of reality, and therefore authorities started using this tool for law enforcement since the 1840s: “Given its material features and its cultural value as an objective form of representation, the camera provided the perfect tool for the documentation, classification, and regulation of the body within the carceral network” (Finn, 2009, p. 29).
Indeed, at first, as the concept of “mug shot” was developing, photos of individuals in the Register lacked a unique formatting, which started to appear in the 1890s. Indeed, as claimed by Finn (2009), mug shots developed from the Nineteenth-century portrait. These portraits featured an individual sitting, with no facial expression, and were usually taken from the front. As it can be seen, the first few mug shots look more like portraits compared to the later ones. For example:

Fig 1: two mug shots from the Register of the Returned Convicts (1869-1939). The first one, depicts Ann Mc Govern, released in 1872. The second one is the mug shot of John Proctor, discharged in 1893.
According to Holligan and Maitra (2018, p. 173), mug shots were established and developed in a milieu of “pessimism about classes of society”. Moreover, the development of criminal anthropology led to a more wide-spread use of photography in carceral settings. Scholars of this field of studies, such as Cesare Lombroso, believed that certain physical characteristics could yield the identification of criminals. The believed objectivity of photography meant that mug shots could further inform these studies; as characteristics found in mugshots could be analysed by criminal anthropologists. At the same time, the popularity of criminal anthropology led this field of studies also to shape law enforcement practices; first and foremost, by shaping the practices of mug shots taking and of noting distinguishing marks.
Specifically, mug shots were introduced in the UK thanks to the above-mentioned Prevention of Crimes Act of 1871: “Under the section 7 of the Prevention of Crime Act 1871 it was recommended that convicted prisoners be photographed before release, full and side face,measurements in millimetres and feet and inches to be made of length and width of head, and lengths of arms,feet and left middle finger including the papillary ridges of the ten fingers as well as distinctive marks by position on body” (Holligan & Maitra, 2018, p. 177). Indeed, Holligan and Maitra (2018) contend that the development of criminal anthropology led to the belief that “habitual criminals” could be identified by some specific marks; such as the length of imbs. Some of these marks were collected and published by the British Registry of Distinctive Marks, which regulated and influenced the ways in which authorities saw and noted distinguishing marks on prisoners.
Ultimately, we aim to argue that this Victorian construction of crime and of the criminal influenced the way in which the register is composed as well, and that the meaning of “crime” and “criminal” are dictated by moral and social standards. Indeed, many were arrested due to charges of Theft “Habit & Repute” which, according to Dr. Darby, means considering someone’s as having a “bad character, a bad name for theft specifically, and that other witnesses considered him a bad person”. Analysing the register means considering those social rules that shaped the way in which the register is written.
It is in our opinion fundamental to acknowledge such dimensions of the register as we open its data. It is in fact important to recognize that “Registers are political” (Ziegler, 2020), and that therefore the categories of the register are constructed. However, it must also be acknowledged that their construction does not make these categories any less impactful on individuals’ lives. Indeed, this is why we embrace attempts such as that of Phil, who tried to retrieve the humanity of the individuals in the register by associating their mug shots to stories; as we shall argue in the next paragraph.
Why this project is important: how did everything start?
Phil Astley explained that the interest in the register was built up during the 2019 and 2020 Granite Noir festival exhibitions, to which the Archives provided 19th century wanted posters, photos of 1930s crime scenes, as well as mug shots contained in the Register.
Indeed, the mug shots had attracted a positive response, and Phil started the Criminal Portraits blog, in which he started exploring the stories of returned convicts whose mug shots are contained in the register. Therefore, Phil has published more than 50 blog posts, drawing on heterogeneous sources, such as newspapers of the time and censuses. The blog has attracted more than 20 thousand views.
In discussing the plans for this project with Phil and Ian Watt of Code The City we agreed that opening up the data contained in the register – making it available as Open Data – would have social and other benefits.
According to the Open Data Handbook, open data is data that can be easily available and re-usable by anyone. There are many values pertaining to open data. Indeed, it can allow for more transparency, and therefore institutions’ or organizations’ accountability. Moreover, it can also prompt economic participation and investment by private companies. Finally, open data can enable citizen participation and engagement, as it is with this project.
In this specific case, we decided to open data from the register precisely because of the public interest it attracted. Not only is the life of the individuals contained in the register fascinating in itself, but we would argue that opening up this data has also a greater social value. For example, it would allow for individuals with a genealogical interest to find out more about their possible ancestors; or it could be useful for researchers who are carrying out their work on criminality in Scotland.
In any case, opening up data from the Archives could lead to more interest towards their rich collections, as well as to a more thorough understanding of these collections’ communal utility.
It was agreed that we would use Wikidata as the place to host the data, given Code The City’s and Ian’s knowledge of, and enthusiasm, for this platform.
How we made the data available
In the second part of this blog we will detail how we transcribed the data, prepared it for Wikidata, uploaded it in bulk, published mugshot photos and linked those.
References
Astley, P. [Aberdeen Performing Arts]. (2021, February 23). Phil Astley – Criminal Portaits Webinar – Granite Noir 2021 [Video]. YouTube.
https://www.youtube.com/watch?v=UFcOG_7Cv0I&t=2346s
Darby, N. (2014, 11 28). The ‘habit and repute’ thief in Scottish law. Retrieved from Dr Nelly Darby. Criminal Historian:
www.criminalhistorian.com/the-habit-and-reute-thief-in-scottish-law/
Finn, J. M. (2009). Capturing the criminal image: From mug shot to surveillance society. U of Minnesota Press.
McLean, R., Maitra, D. E. V., & Holligan, C. (2017). Voices of quiet desistance in UK prisons: Exploring emergence of new identities under desistance constraint. The Howard journal of crime and justice, 56(4), 437-453
Open Knowledge Foundation. (n.d.). Open Definition: Defining Open in Open Data, Open Content and Open Knowledge. Retrieved from Open Knowledge Foundation:
https://opendefinition.org/od/2.1/en/
Radzinowicz, L., & Hood, R. (1980). Incapacitating the habitual criminal: The English
experience. Michigan Law Review, 78(8), 1305-1389.
Ziegler, S. L. (2020). Open Data in Cultural Heritage Institutions: Can We Be Better Than Data Brokers?. Digital Humanities Quarterl, 14(2).










{kind=link}