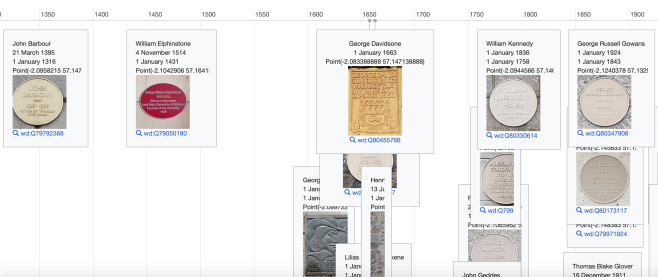
Code The City is a civic hacking initiative focused on using tech and (open) data for civic good. We use hack weekends, open data, workshops, and idea generation tools. We run Data Meetups, the Aberdeen Python User Group and the annual Scottish Open Data Unconference
To identify (all of) the settlements – towns, hamlets, villages – in Aberdeenshire and ensure that these are well represented with high quality items on Wikidata and Wikipedia.
Aims
Identify one or more lists of settlements in Aberdeenshire
Use those lists to identify gaps in Wikipedia and WIkidata for Aberdeenshire settlements.
Create Wikidata items, update Wikipedia with a more comprehensive list of settlements and, time permitting, enhance existing Wikipedia articles with Infoboxes, and create new Wikipedia articles where these are missing.
Approach
We began by importing a list from Wikipedia into Google Sheets using its function
=importHTML(url, item, position)
This gave a list of 183 settlements – with five having missing Wikipedia articles.
To compare, we then wrote an initial Wikidata query which only returned 10 results. It turned out that there are two (or more) Aberdeenshires in Wikidata (each representing something subtly different) and we used the wrong one.
Amending our query and running the new one gave us 283 settlements. On checking we saw that they included the 10 above too. It also included whether the item had a Wikipedia article associated with it. We used this Wikidata list (with a quick python script) to update the original Wikipedia list page above.
Adding Images / WikiShootMe
We further updated the query adding whether there was a photo associated with the item giving firstly these results and, by changing the default view to map, we could see where the coordinates were placing each point. The vast majority (est. 90% ) of items had no photograph.
By following this tutorial that Ian had created recently, we were able to create a custom clickable map in the WikiShootMe tool. This means that anyone can click on a red dot, and choose to take or upload a photo of the settlement and have that added to Wiki Commons, and associated automatically with the Wikidata item.
We published that on Twitter and asked for contributions. Not only could someone take and upload a photo, but it also meant that one could search Wiki Commons for a matching image (which hadn’t yet been associated with the Wikidata item) and tell it to use that. Where none existed it was possible to search on Geograph for a locality. The licensing on Geograph is compatible with Wiki Commons’s terms, so if a suitable image was available, we could use the Geograph2Commons tool and import it.
Over the next few days (i.e. beyond the weekend itself), we went from a starting point of about 10% of settlements in Wikidata having photos to about 90%. You can see this on an image grid, or table.
Red dots show missing photos; green, ones found
Updating Coordinates
Looking closer at the mapped Wikidata, a number of the items’ coordinates were well out (e.g. Rosehearty, Sandhaven New Aberdour etc). We started to fix these. We did this by finding the settlements in our WikiShootme map, right clicking on the correct position and selecting show coordinates, and pasting those back into the Wikidata item.
Where the original coordinates were imported from Wikipedia it raised a warning. We fixed each one in Wikipedia too, as we went. This needs much more error checking and fixing.
Fixing coordinates and uploading images
Missing Places
Our list of places started at 183 links on wikipedia, it grew to 283 with wikidata but still it was clear that many of the populous settlements are missing from Wikidata such as Fintry.
Fintray missing
These can be added manually but we figured there must be a larger list available from another source like OpenStreetMap (OSM). Not knowing how to get this list we put out a tweet for help.
A tweet for help
@MaxErickson was one those that came to our aid with a query search for overpass turbo (a web-based data filtering tool for OpenStreetMap) which listed all its identified places in Aberdeenshire with coordinates and place types (town, village, hamlet). This gave us over 780 results but many of these were farm steadings or small islands (islets) in the Ythan, with a bit of filter we got it down to 629 places. We plan to add these to Wikidata, but first it’s worth gathering more data on them.
MySociety
We wanted to add more information to these place such as which constituency each was in for Scottish and UK elections. The Boundary Commission for Scotland website has a tool which lets you enter a postcode and returns this information:
Querying the Boundary Commission for Scotland website
After digging around their website we found that they use mapit.mysociety api to do this. Mapit is open-source software but there is a charge for using their api, luckily CodeTheCity is a charity and eligible for free usage so Ian signed us up! The API accepts a variety of inputs including lat/lon which we got from the turbo query of OSM.
With a bit more python scripting we now have a CSV with 629 places each listed with coordinates, Scottish Parliament region, Scottish Parliament constituency, UK parliament constituency, Health Board and Unitary Authority.
A spreadsheet of enhanced data for Aberdeenshire settlements
What Next?
We are going to get the csv uploaded to Wikidata via Quick Statements, to add the missing places, update existing places with Mysociety data and correct any wandering coordinates in wikidata/wikipedia.
Check the Wikidata list with the OSM list for any missing places in the OSM list (ensuring that core data for each place is included).
Add more information to our CSV to allow us to populate Wikipedia infoboxes for these places. This would include
Altitude
Distance from London (UK Capital)
Distance from Edinburgh (Scotland Capital)
Postcode district(s)
Dial Code(s)
Population (may be difficult for smaller settlements)
Area (may be difficult for smaller settlements)
Update Wikidata with new places and any edits required to existing places
Update Wikipedia List page as a table from this data.
This application is designed to be used on a mobile phone. It allows you to call up a map of where you are at the moment and find missing images of listed building (as red dots). You can then authorise the app, using your Wikipedia / Wikidata credentials, and click on a red dot to upload a photo that you either take there and then or from your phone’s media. The image goes straight to Wiki Commons with a CC-BY-SA licence. And, once uploaded, the photos are automatically linked to the wikidata entry for that item! Should that be automagically?
I had a bunch of projects where I thought it would be useful to generate a custom map with missing images (for example of plaques, or boundary stones), then encourage people to photograph them and add them. Thankfully, Wikishootme allows you to do that.
It turns out it’s not too hard to do. Here is a walk through.
1. Create your wikidata query
I’m going to use the March Stones of Aberdeen as an example. I suggest that you copy exactly what I do, creating this query in full through all three steps. Then when you understand how it works, substitute your own query.
In Wikidata’s Query Service, create the query to retrieve the data you want. Wikishootme is quite particular about column names in the final output, so we need to make sure that our query has columns called ‘q‘ (for the wikidata identifiers) and ‘location‘ for the coordinate locations.
(For the purposes of this tutorial it is not necessary to understand the syntax of a SPARQL query. If you are curious, in the above query P31 means an instance of; Q921099 is the identifier for a boundary marker;P131 means located in the administrative entity; and Q62274582 is Aberdeen City)
Test that your query runs ok and returns what you expect. The query above will generate a table with two columns – one labelled q with a list of Wikidata QID codes, and another, location with coordinate pairs for each item.
2. Grab the SPARQL
Next copy all of the code between the {} pair (i.e. all of the second and third lines of the query above, but without the curly braces.
This will create a stream of characters that can be passed as part of a URL to another service. Copy all of that text. When I encode the query above I get the following string:
Click on the link above. Did it work? It does for me. When I open it it defaults to a whole world map.
Default view of Wikishootme
Scroll and zoom to where your red dots are.
Wikishootme, scrolled and zoomed
Tip: when you get the map centred and at the scale you like, recopy the URL. This will capture the location and zoom level in your map for sharing.
Also, click on the layers symbol at the top right of the map. Choose to display where the data has images (green) as well as the red:
Wikishootme Layers control
That will change your view to showing red (missing) and green (captured) images for your wikidata items. This will give the URL such as this which loads the map correctly centred. at the right scale, and showing the layers you want.
Wikishootme showing red and green dots
Now you can share your map. I suggest copying your URL (see the Tip above) into a link shortener such as bit.ly so as to make sharing easier.
Now, when someone clicks on your URL they can click on a red dot, and upload a missing photo to Wiki Commons, and automatically link it to Wikidata – and turn those red dots green!
In the run up to Code The City 19 we had several suggestions of potential projects that we could work on over the weekend. One was that we add all of the Provosts of Aberdeen to Wikidata. This appealed to me so I volunteered to work on it in a team with Wikimedia UK’s Scotland Programme Coordinator, Dr Sara Thomas, with whom I have worked on other projects.
In preparation for CTC19 I’d been reading up on the history of the City’s provosts and discovered that up to 1863 the official title was Provost, and from that point it was Lord Provost. I’d made changes to the Wikipedia page to reflect that, and I’d added an extra item to Wikidata so that we could create statements that properly reflected which position the people held.
Sara and I began by agreeing an approach and sharing resources. We made full use of Google Docs and Google Sheets.
We had two main sources of information on Provosts:
Wikipedia, which I suspect draws on the former although there are date discrepancies.
Running the project
I started by setting up a Google Sheet to pull data from Wikipedia as a first attempt to import a list to work with. The importHTML function in Google Sheets is a useful way to retrieve data in list or table format.
and repeating the formula for all the lists – one per century. This populated our sheet with the numerous lists of provosts.
That state didn’t last very long. The query is dynamic. The structure of the Wikipedia page was being adapted, it appeared, with extra lists – so groups of former provosts kept disappearing from our sheet.
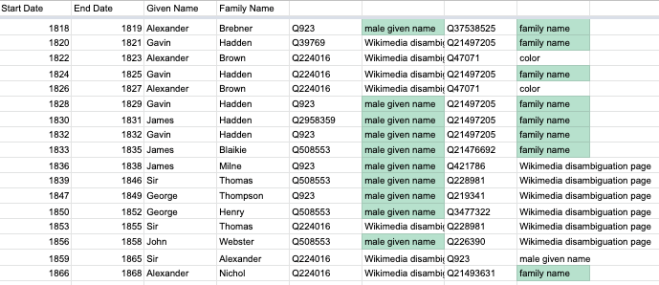
I decided to create a list manually – copying the HTML of the Wikipedia page and running some regex find and replace commands in a text editor to leave only the text we needed, which I then pasted into sheets.
Partial list of Lord Provosts
Once we had that in the Google Sheet we got to work with some formulae to clean and arrange the data. Our entries were in the form “(1410–1411) Robert Davidson” so we had to
split names from dates,
split the start dates from end dates, and
split names into family names and given names.
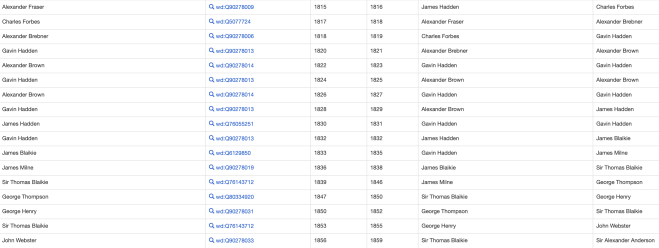
Having got that working (albeit with a few odd results to manually fix) Sara identified a Chrome plugin called “Wikipedia and WikiData tools” which proved really useful. For example we could query the term in a cell e.g. “Hadden” and get back the QID of the first instance of that. And we could point another query at the QID and ask what it was an instance of. If it was Family Name, or Given Name we could use those codes and only manually look up the others. That saved quite a bit of time.
Identifying QIDs for Given and Family Names
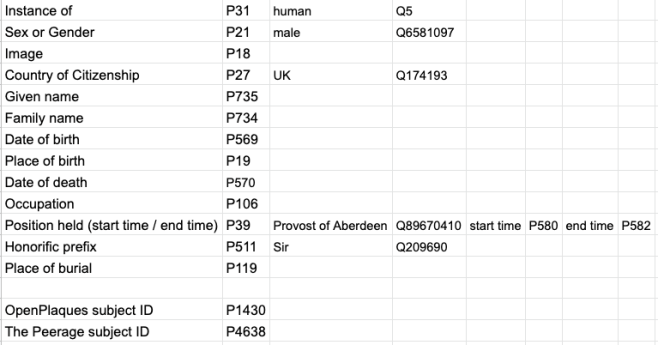
Our aim in all of this was to prepare a bulk upload to Wikidata with as little manual entry as possible. To do that Sara had identified Quickstatements, which is a bulk upload tool for Wikidata, which allows you to make large numbers of edits through a relatively simple interface.
Sara created a model for what each item in Quickstatements should contain:
A model of a Quickstatements entry
There are a few quirks – for example, how you format a date – but once you’ve got the basics down it’s an incredibly powerful tool. The help page is really very useful.
Where dates were concerned, I created a formula to look up the date in another cell then surround it with the formatting needed:
="+"&Sheet1!J99&"-00-00T00:00:00Z/9"
Which gave +1515-00-00T00:00:00Z/9 as the output.
You can also bulk-create items, which is what we did here. We found that it worked best in Firefox, after a few stumbles.
Data harvesting
As mentioned above, we used a printed source, from which we harvested the data about the individual Provosts. It’s easy to get very detailed very quickly, but we decided on a basic upload for:
Name
First name
Last name
Position held (qualified by the dates)
Date of birth, and death (where available).
Some of our provosts held the position three or four times, often with breaks between. We attempted to work out a way to add the same role held twice with different date qualifiers, but ultimately this had to be done manually
The first upload
We made a few test batches – five or six entries to see how the process worked.
A test batch to upload via Quickstatements
When that worked we created larger batches. We concluded the weekend with all of the Provosts and Lord Provosts being added to Wikidata which was very satisfying. We also had a list of further tasks to carry out to enhance the data. These included:
Add multiple terms of office – now complete,
Add statements for Replaces (P1365) and Replaced By (P1366) – partly done,
Add honorific titles, partly done
Add images of signatures (partly done) and portraits ( completed) from the reference book,
Add biographical details from the book – hardly started,
Source images for WIkiCommons from the collection portraits at AAGM – request sent,
Add places of burial, identifiers from Find A Grave, photographs of gravestones,
In part one I described what we did at CTC18 to capture data and images of Commemorative Plaques in Aberdeen, and what I then did in the following three weeks.
A few people asked my why we would bother to put plaques into Wikidata and WikiCommons in this way. Why not have a council website – or why not use Open Plaques?
In this second instalment I am going to demonstrate how we can use the data which we have created to make some interesting visualisations and even do some calculations and analysis.
It can also power other new apps and services – allowing developers to create tailored routes around the city, on themes such as the arts or medicine – which is beyond the scope of this post.
Getting Started
At the time of writing we now have 132 Aberdeen Commemorative Plaques recorded in Wiki Data.
I can check that with this simple query on the Wiki Data Query Service:
Plaques – Query One
All that this does is ask for every instance (P31) of a commemorative plaque (Q721747) whcich is located in (P131) the Aberdeen City (Q62274582) area.
Click on the white-on-blue arrow at the left. See what it produces. Note the bottom half of the screen turns into a table of results, and on the centre bar there is a message ‘xxx results in xxxx milliseconds‘.
How many pictures of plaques?
I can retrieve the photograph for plaque using the following query.
Plaques – Query Two
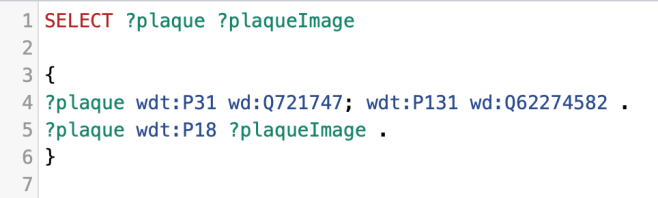
Here I am saying give us plaques which have image (P18). In effect this is saying ONLY those that have an image. If not all entries have an image, yet, then we will get a smaller number.
As I run it I get 126 – which is six fewer than I got plaques.
Get all plaques with images or not
Let’s modify the query to this.
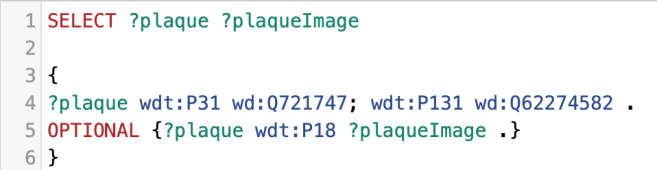
Plaques – Query Three
Here I am the OPTIONAL command which has the effect of saying IF there is an image give me it, but don’t restrict the results to only those with images. When we run that we can spot the missing ones by scrolling down through the list. I get six plaques with no images. This is a useful technique to spot missing things when totals (in this case plaques and images) don’t tally.
As it stands the query is still not very user-friendly as all we have for the plaques is their Plaque ID. Of course we can click on those, but it would be more helpful to have the names of their subjects.
We’ll do that in two steps.
Firstly, let’s work out what the subjects are.
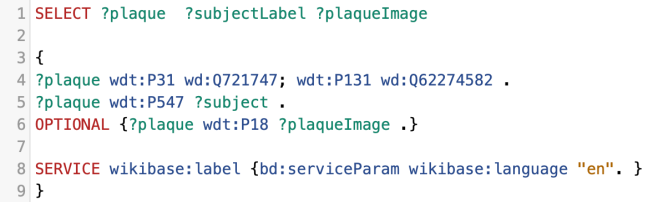
We can add the following line to the query and remember to add ?subject to the SELECT on the first line.
If we run that we get a new column called subject and it is filled with links to subject IDs, which are the Wikidata entries for either people or things that the plaques commemorates. I note that when I run it my list has grown from 132 to 134.
Any guesses why that should be?
Some of the plaques commemorate more than one person.
Let’s make it a bit more friendly.
Add the following line just before the end of your query
SERVICE wikibase:label {bd:serviceParam wikibase:language "en". }
And change ?subject to ?subjectLabel in the first line.
This instructs the WikiData Query service to use another service to retrieve labels from the items.
Plaques – Query Four
The label is in effect the title of the Wikidata item. Look at this one https://www.wikidata.org/wiki/Q80818579 Immediately below the title, and to the left, there is an edit link. Click that. See how the ‘label‘ and the ‘description‘ immediately below it become editable. Cancel that for now.
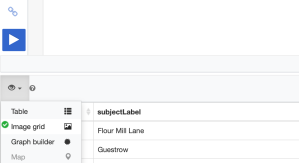
At this point you might want to change the view for your query just to have a look at the images we have.
Above the table of results, on the extreme left there is an eye symbol and a drop down. Choose “Image Grid” to see the images only.
Plaques – change view
You might also have noticed that there are other options, several of which are greyed out as we don’t yet have that data in our query. These views include ‘Map‘ and “Timeline‘. We’ll come back to those.
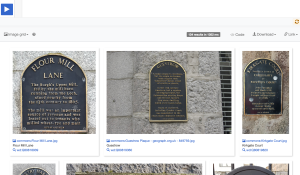
Our Image Grid looks something like this:
Plaques – Image Grid
Remember to swap back to ‘Table’ view once you’ve finished.
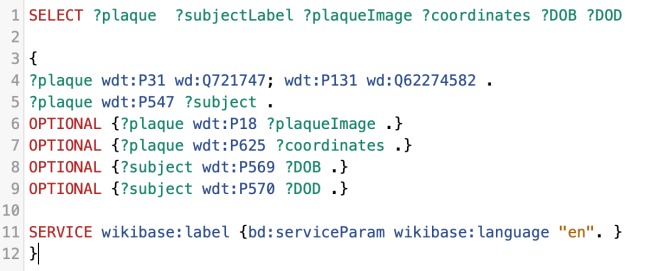
Adding more data fields
We can now add more data fields to our query.
Firstly, let’s add the geographic coordinates of the plaques’ locations.
Add the following line to your code:
OPTIONAL {?plaque wdt:P625 ?coordinates .}
and, again add the new value, ?coordinates to the first line of the query too.
You will now have an extra field in the returned data table.
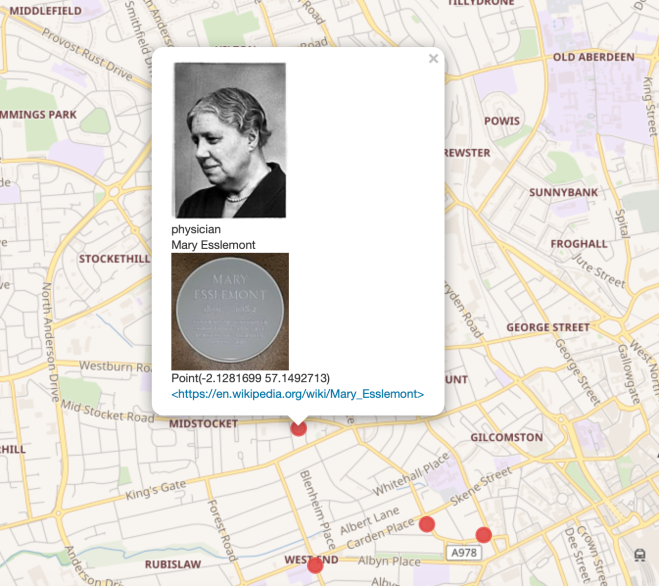
Now change the view from Table to Map. The Wikidata query service automatically uses the coordinates to plot the results on a map which is scaled to show the results. You may need to scroll down to see all of the map. Click on one of the plotted points. You should get a pop up with the name of the person or building commemorated, plus a photo of the plaque itself, as shown below.
Plaques – map view
Note – if you add the following as the first line of your query, it will default to a map view rather than table when first run.
#defaultView:Map
Now let’s see if we can get more data for the people for whom there are plaques.
Dates of birth and death
We can change our query to find out if there are dates of birth and death for our human subjects (rather than buildings).
We can use P569 (date of birth) and P570 (date of death) and ascribe those to
?DOB and ?DOD respectively – again, adding those fields to our SELECT statement on line one. Your query should look like this?
Looking at our table of results we can see that we have a mix of types of results – people, bridges, buildings etc. but only the people have dates.
Table showing dates of birth
Interestingly the one subject with the DOB and DOD in the screenshot above is Elizabeth Crombie Duthie who gifted Duthie Park to the city of Aberdeen.
Remember, if you change the DOB and DOB from being OPTIONAL to just being regular requests, you can filter records to show ONLY those with dates associated with them which will screen out not only non-human subjects but will exclude any people with incomplete or missing dates.
Notable people
It could be argued that the fact there is a plaque to a person would indicate that they are notable, but not every person or object for which there is a plaque has a Wikipedia article. Let’s add some code to see which of our plaques has an associated article.
Changing the above so that we remove the OPTIONAL {} around the section beginning ?article we get ONLY those with Wikipedia articles which is, as I run it, 79 plaque subjects.
You can if you want we add the following
?subject wdt:P31 wd:Q5 .
where P31 (instance of ) is Q5 (human) we can screen out all of the non-people plaques.
At this point, try flipping the view to TimeLine – you may have to scroll down quite a way to see all of the plaques. Many of them are concentrated at the right, spanning much of the 20th century. You should see John Barbour (1316-1395 at the extreme left).
Plaques – timeline
Finally, before we start doing some statistical analysis let’s try something more sophisticated.
Can we create a map showing only female subjects whose work was in the medical sciences?
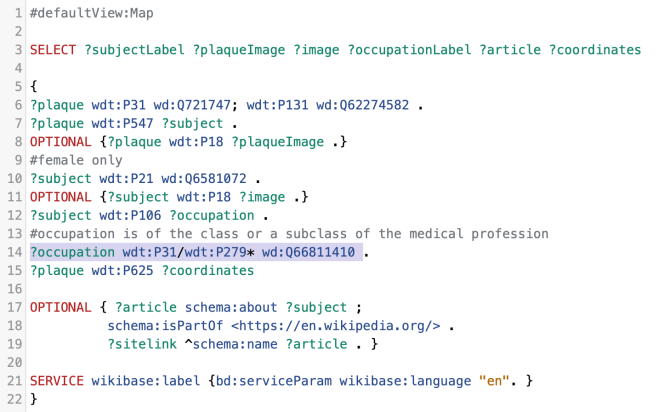
To do that we need to select only subjects who have a P21 (gender or sex) of Q6581072 (female). Then we need to select an occupation (P31) which is an instance or subclass of Q66811410 (the medical profession). This requires a structure that we haven’t see before:
?occupation wdt:P31/wdt:P279* wd:Q66811410
While we are at it, let’s get an image of the subject if there is one, and find out of there is a wikipedia article about the subject. And, since we want a map, we add that as our default view at the top.
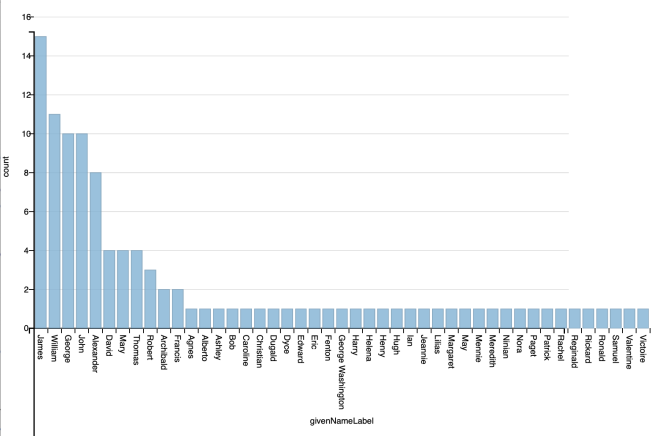
With 81% of plaques to people being for males it is hardly surprising that our league table of names begins with James, William, George, John, Alexander ….
We can do more sophisticated analysis too.
Analysing Occupations
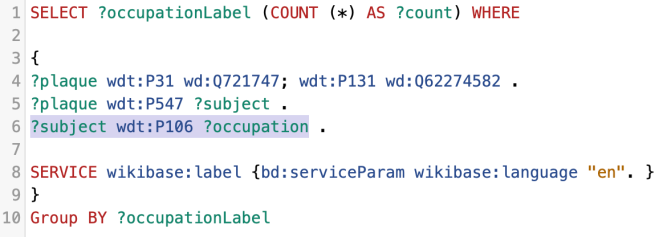
We can add the following line to our query to get back the occupation of the subject of the plaque:
?subject wdt:P106 ?occupation
Bear in mind that many of our plaque subjects are true polymaths. Have a look at Robert Brown. He has 10 listed occupations!
So what are the most common occupations of those people for whom there are plaques? Any guesses?
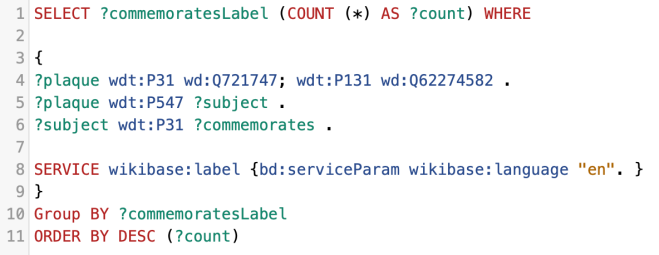
Let’s use the following query:
Plaques – Using Count()
This uses the COUNT () function as well as a GROUP BY clause. The query looks at all of the different occupation labels, counts how many of each there are.
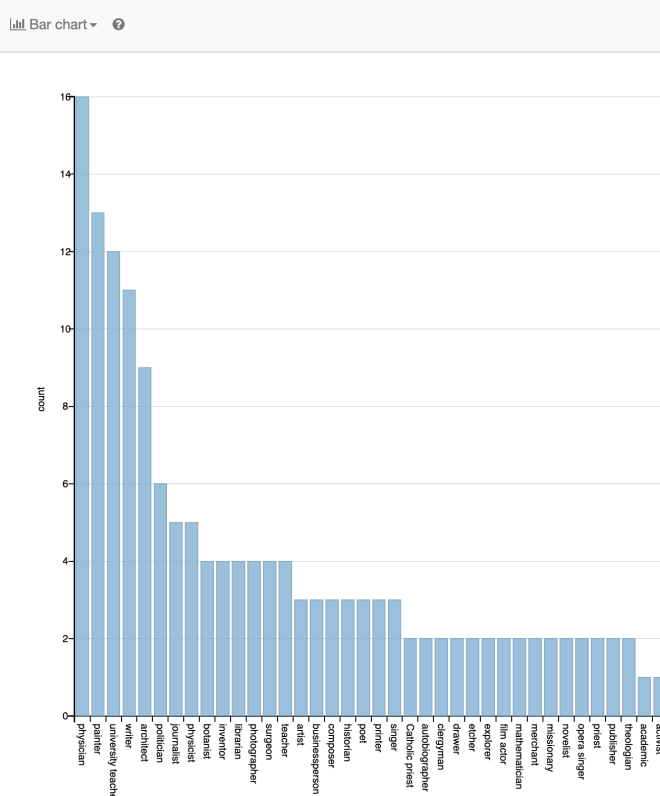
This returns, by default, a table of values. We can flip to a Bar Chart to make better sense of the data:
Plaques – Bar Chart of occupations
So, we can see that for those commemorated by a plaque the most common occupations are Physician, Painter, University Lecturer, Writer and so on.
We can add a couple of refinements if we wish. If we want our query to default to a BarChart when we run it we can add the following line at the start of the query:
#defaultView:BarChart
and if we want the table to be sorted by value we can add a line such as
Over the last month I’ve been busy gathering data, taking photographs and publishing all of those on WikiData and wiki Commons. That phase is not quite complete, if it ever could be considered complete. You can monitor live progress here.
There are a couple of photographs which I can’t easily take which I know Aberdeen City Council’s Museum and Galleries team have. It would be great to see those made available by them on Wiki Commons, as I have shared the 148 plaque photos I have taken.
I know of at least 24 more plaques which I have photographed which are not listed yet in Wikidata.
When I published part one of this series I got some great feedback on Twitter. One suggestion is that we add structured data to the Wiki Commons pages for each photograph. Another was to add further data to the record for each plaque using statement P276 (location) where the plaque is on a known listed building. So far I have done that for 5 plaques – check it for yourself. There are loads more to do.
Many of the people records that I have created in Wikidata are skeletal. They need more detail, photographs, biographical links etc. Similarly, given that people or places are noteworthy enough to merit a plaque, they should pass the notability test for Wikipedia, yet at least 68 plaque subjects have no Wikipedia entry.
And plaques are just a start – an easy introduction to what is possible given, in this case, about 100 hours of work. While that was almost all done by one person, if we ran a Code The City weekend on a similar theme and similar sized challenge, six people could achieve the same over a weekend with a little coordination.
At Code The City, we’re about to start discussions with the local cultural institutions about setting up a more formal alliance for the city (shire?) to help shape how they use digital and data more effectively and grow volunteers with skills and tools to make that happen, which is an exciting note on which to finish this post! Watch this space, as they say.
The evening before Code The City 18 I started to think about what fun project to spend the day doing at our one day mini-hack event. After reading Ian Watt’s blogpost about Wikidata and spending 10 minutes or so playing around with it, I decided a topic for further experimentation was required.
At the time of writing, I’m just over a third of the way through my very interesting part-time online MA Railway Studies at University of York. Looking at Britain’s railways from their very beginning, there are many railway companies from 1821 onwards. Some of these companies merged, some were taken over, others just disappeared whilst others were replaced by new companies. All these amalgamations eventually led to the “Big Four” groupings in 1923 and then on to British Railways in 1948’s railway nationalisation. British Railways rebranded as British Rail in 1965 and then splintered into numerous companies as a result of the denationalisation of the 1990s.
With the railway companies appearing in some form or another in Wikipedia, I thought it would be useful to be able to pick any railway company and view the chain of companies that led to it and those that followed. The ultimate goal would be to be able to bring up the data for British Rail and then see the whole past unfold to the left and the future unravel to the right. In theory at least, Wikidata should allow me to do that.
No software coding skills are required to see the results of my experimentation: by clicking on the links provided (usually directly after the code) it is possible to run the queries and see what happens. However, using the code provided as a start, it is possible to build on the examples to find out things for yourself.
Understanding Wikidata and SPARQL
SPARQL is the query language used to retrieve various data sets from Wikidata via the Wikidata Query Service.
As is always the case with anything software related, the examples and tutorials never seem to handle those edge cases that you seem to hit within the first 5 minutes. Maybe I hit these cases so soon due to jumping straight from the “hello world” of requesting all the railway companies formed in the UK to trying to build the more complex web of railway companies rather than working my way through all the simpler steps? However, my belief is to fail quickly, leaving plenty of time left to fail some more before succeeding, after all you never see a young child plan out a strategy when they are learning to get the different shaped blocks through the correct holes.
At the time of writing…
Comments about the state of certain items of data were relevant at the time I wrote this article. As one of the big features of Wikidata is it constantly being updated, expanded and corrected, the data referenced may have changed by the time you read this. Some of the changes are those I’ve made in reaction to my discoveries, but I have left some out there for others to fix.
A simple list
First off, I created a simple SPARQL query to request all the railway companies that were formed in the UK.
SELECT ?company ?companyLabel WHERE { ?company wdt:P31 wd:Q249556; wdt:P17 wd:Q145 . SERVICE wikibase:label { bd:serviceParam wikibase:language “en”. } } ORDER BY (lcase(?companyLabel))
The output of this query can be seen by running it yourself here by clicking on the white-on-blue arrow displayed on the Wikidata Query Service console. It is safe to modify the query in the console without messing up my query as any changes cause a new bookmarked query to be created. So please experiment as that’s the only way to learn.
Now what does the query mean and where do all those magic numbers come from?
wdt:P31 means get me all Wikidata triples (wdt) that have the property instance of (P31) that is has a value of railway company (Q249556).
wdt:P17 means get me all of the results so far that have the property country (P17) set to United Kingdom (Q145).
Where did I get those numbers from? First, I went to Wikipedia and searched for a railway company, LMS Railway, and got to the page for London, Midland and Scottish Railway. From here I went to the Wikidata item for the page.
Wikipedia page for LMSR that shows how to get to the Wikidata
From here I hovered my pointer over instance of, railway company, country and United Kingdom to find out those magic numbers.
Wikidata page for LMSR
Some unexpected results
Some unexpected companies turned up in the results list due to my query not being specific enough. For example, Algeciras Gibraltar Railway Company, located in Gibraltar but with headquarters registered in the UK the data has its country as United Kingdom. To filter my results down to just those that are located in the UK I tried searching for those that had the located in the administrative territorial entity (P131) with any of the following values:
However, that dropped my result set from 228 to 25 due to not all the companies having that property set.
Note: When trying to find out what values to use it is often quick and easy to run a simple query to ask Wikidata itself. To find out what all the values were for UK countries I wrote the following that asked for all countries that had an instance of value of country within the United Kingdom (Q3336843):
select ?country ?countryLabel WHERE { ?country wdt:P31 wd:Q3336843 . SERVICE wikibase:label { bd:serviceParam wikibase:language "en". } }
In order to see what other information could easily be displayed for the companies, I looked at the list of properties on the London, Midland and Scottish Railway. I saw several dates listed so decided that would be my next area of investigation. There is an inception (P571) date that shows when something came into being, so I tried a query with that:
SELECT ?company ?companyLabel ?inception WHERE { ?company wdt:P31 wd:Q249556; wdt:P17 wd:Q145 . ?company wdt:P571 ?inception SERVICE wikibase:label { bd:serviceParam wikibase:language "en". } } ORDER BY (lcase(?companyLabel))
This demonstrated two big issues with data. Firstly, the result set had dropped from 228 to 106 indicating that not all the company entries have the inception property set. The second was that only one, Scottish North Eastern Railway, had a full date (29th July 1856) specified, the rest only had a year and that was being displayed as 1st January for the year. Adding the OPTIONAL clause to the inception request returns the full data set with blanks where there is no inception date specified.
SELECT ?company ?companyLabel ?inception WHERE { ?company wdt:P31 wd:Q249556; wdt:P17 wd:Q145 . OPTIONAL { ?company wdt:P571 ?inception. } SERVICE wikibase:label { bd:serviceParam wikibase:language "en". } } ORDER BY (lcase(?companyLabel))
Railway companies are not a straightforward case when it comes to a start date due to there being no one single start date. Each railway company required an Act of Parliament to officially enable it to be formed and grant permission to build the railway line(s). This raises the question: is it the date that Act was passed, the date the company was actually formed or the date that the company commenced operating their service that should be used for the start date? Here is a revised query that gets both the start time (P580) and end time(P582) of the company if they have been set:
Unfortunately, of the 228 results only one, London, Midland and Scottish Railway, has a startTime and endTime, and London and North Eastern Railway is the only with endTime. Based on these results it looks like that startTime and endTime are not generally used for railway companies. Looking through the data for Scottish North Eastern Railway did turn up a new source of end dates in the form of the dissolved, abolished or demolished (P576) property. Adding a search for this resulted in 9 companies with dissolved dates.
There is no logic in which companies have this property: they range from Scottish North Eastern Railway dissolving on 10th August 1866 to several that ended due to the formation of British Railways, the more recent British Rail ending on 1st January 2001, and the short lived National Express East Coast (1st January 2007 – 1st January 2009). However, once again, the dates are at times misleading as, in the case of National Express East Coast, it is only the year rather than full date in the inception and dissolved, abolished or demolishedproperties.
Some of the railway companies, such as Underground Electric Railways Company of London, have another source of dates and that is as part of the railway company value for their instance of. It is possible to extract the start and end dates if they are present by making use of nested conditional queries. In the line:
Another date that can be used to work out the start and end of the companies can be found hanging off the values of very useful pair of properties: replaced by (P1366) and replaces (P1365). This conveniently connects into the next part of my exploration that will follow in Part Two. Although, as with many railway related things, the exact time of arrival of part two cannot be confirmed.